



개발공부, 프로젝트한거 정리하는 블로그
들어가며
AI 코딩 도구(Claude Code, Devin 등)를 실무에서 적극 활용하면서 한 가지 예상치 못한 문제를 발견했다. AI가 코드베이스의 로그 메시지를 "사실"로 받아들여, 잘못된 방향으로 문제를 진단하는 현상이다.
로그가 말하는 것 vs 실제로 일어나는 것
로그는 작성자의 가설이다
로그 메시지는 코드를 작성한 사람이 "이 시점에 이런 일이 일어날 것"이라고 가정한 내용이다. 하지만 시스템이 복잡해지면 그 가설이 틀릴 수 있다.
예를 들어, 분산 스트리밍 환경에서 이런 로그가 있다고 가정하자:
이 로그는 "A가 누락된 것"이라고 단정하고 있다. 하지만 실제로는 A가 생성되었으나, 병렬 처리 과정에서 B보다 늦게 도착한 것일 수 있다. 즉, 누락이 아니라 순서 역전이다.
사람도 속고, AI도 속는다
사람은 이런 로그를 보면 "아, A가 누락되는구나"라고 생각하고 누락 방지 로직을 추가하려 한다. AI도 마찬가지다. 코드베이스에서 이 로그를 발견하면 "A 누락" 전제 하에 해결책을 제안한다.
문제는, AI는 로그 메시지를 의심할 동기가 없다는 것이다. 코드에 적혀 있으면 그것이 사실이라고 판단한다. 이것이 AI 에이전트의 확증 편향이다.
왜 위험한가
1. AI가 잘못된 전제 위에 해결책을 쌓는다
AI 에이전트가 잘못된 로그에 속을 때 — 확증 편향과 로그 정합성
2026/02/01
생각 정리
Devops
키워드 정리중
들어가며
실무에서 사용하는 오픈소스가 요구사항을 "거의" 충족하지만, 딱 하나가 안 되는 경우가 있다. 이때 선택지는 보통 세 가지다:
1.
다른 방식으로 직접 구현
2.
다른 레이어에서 우회
3.
오픈소스를 커스텀
이 글에서는 실제로 오픈소스 커스텀을 선택했던 경험을 바탕으로, 의사결정 프레임워크를 정리한다.
상황: "거의 다 되는데, 하나가 안 된다"
예를 들어, 어떤 파이프라인 프레임워크의 Sink Connector가 JSON 직렬화만 지원하는데, 우리 환경에서는 Avro + Schema Registry가 필수인 상황이라고 가정하자.
이 프레임워크를 쓰면 파이프라인 정의가 YAML 몇 줄로 끝나고, 직접 코드를 작성하면 수백 줄의 코드와 테스트가 필요하다. 포기하기엔 아깝고, 강행하기엔 막히는 지점이 있다.
세 가지 선택지의 트레이드오프
선택지 1: 다른 방식으로 직접 구현
프레임워크를 버리고, 필요한 기능을 직접 코드로 구현한다.
장점: 완전한 제어가 가능. 어떤 요구사항이든 구현할 수 있다.
오픈소스를 커스텀해야 할 때 — 의사결정 프레임워크
2026/01/27
아키텍처
생각 정리
키워드 정리중
들어가며
Claude Code를 사이드 프로젝트에서 적극 활용하면서, AI 에이전트가 생산성을 높여주는 동시에 예상치 못한 문제를 일으키는 것을 경험했다. 아키텍처 규칙을 무시하고, 계획 없이 코드를 수정하고, 위험한 명령어를 실행하는 경우가 반복되었다.
이 글에서는 Claude Code의 Hooks 기능을 활용하여 AI 에이전트가 프로젝트 규칙을 따르도록 강제하는 가드레일 시스템을 설계한 경험을 공유한다.
문제 상황
AI 에이전트를 아무런 제약 없이 사용하면 다음과 같은 문제가 반복된다:
1.
아키텍처 위반: DDD 레이어 규칙(Domain → Infrastructure 의존 금지 등)을 무시한 코드 생성
2.
계획 없는 코드 수정: 작업 계획 없이 바로 src/ 코드를 수정하여 맥락 추적이 어려움
3.
파괴적 명령어 실행: git reset --hard, rm -rf 같은 명령어를 아무 경고 없이 실행
4.
패턴 불일치: 레이어별 문서를 읽지 않고 코드를 작성하여 기존 패턴과 불일치
Claude Code Hooks란?
Claude Code의 Hooks는 AI가 도구(tool)를 사용하기 전후에 사용자 정의 스크립트를 실행할 수 있는 기능이다.
•
PreToolUse Hook: AI가 Bash 명령어, 파일 수정 등을 실행하기 직전에 트리거
Claude Code Hooks로 AI 에이전트 가드레일 만들기
2026/01/10
사이드 프로젝트
프로그래밍 일반
키워드 정리중
들어가며
"느리다"는 리포트를 받았을 때, 어디서부터 봐야 할까? 로그? APM? 프로파일러?
가장 빠르고 확실한 방법 중 하나는 Thread Dump다. 특히 Kubernetes Pod 환경에서, APM이 없거나 설정이 안 된 상태에서 즉시 할 수 있는 것이 Thread Dump다.
이 글에서는 JVM 기반 애플리케이션(Spring Boot 등)의 성능 병목을 Thread Dump로 찾는 실전적인 방법을 정리한다.
Thread Dump란?
Thread Dump는 JVM의 모든 스레드가 "지금 이 순간" 무엇을 하고 있는지를 스냅샷으로 찍은 것이다. 각 스레드의 호출 스택(Stack Trace)이 포함되어 있어, 어떤 메서드에서 시간을 소비하고 있는지 알 수 있다.
Pod 환경에서 Thread Dump 뜨기
방법 1: jstack
방법 2: kill -3
표준 출력으로 Thread Dump가 출력된다. 컨테이너 로그에서 확인할 수 있다.
팁: 여러 번 떠라
Thread Dump로 성능 병목을 찾는 실전 가이드
2025/11/01
Spring
운영
Java
키워드 정리중
스팟잇(Spot It!) 사이드 프로젝트 회고

프로젝트 소개
두 마리 토끼를 잡으려는 건 어리석은 발상이다
개발자가 사이드 프로젝트를 통해 얻을 수 있는 것은 다음과 같이 크게 2가지가 있다.
1.
기술적 학습 및 경험
2.
실제로 유의미한 문제를 해결하는 서비스 출시, 나아가 사업화
현직자에게 사이드 프로젝트란
2025/10/23
팀 프로젝트
사이드 프로젝트
작성 완료
계기
우테코하면서 진행한 프로젝트인 데벨업 프로젝트는 원래 서비스 종료 예정이었으나, 서비스 유지를 원하는 팀원이 있어서 목숨만 부지하고 있었다.
이에 인증서 갱신 등의 작업을 주기적으로 해야 하는데, docker 기반의 인프라로 이를 자동화 하는 것은 상당히 귀찮은 일이다. 마침 회사 업무에서 k8s 를 활용하면서 이런 인증서 발급이나 네트워크 설정들을 k8s 환경에서 구축하는 것이 훨씬 쉽다는걸 깨달았고, 이를 적용해보면 신경쓰지 않아도 될 것 같아 길고 긴 추석 연휴에 이 작업을 수행하게 되었다.
설치 과정
arm VM 생성
오라클 클라우드에서는 익히 알려진대로 arm 기반의 vm 을 4코어 CPU, 24 GB 메모리를 평생 무료로 제공해준다. 하지만, 이런 vm 을 프리 티어 계정에서 생성하는 것은 불가능에 가깝다. 정확히 공지된 바는 없지만, 오라클이 프리티어 사용자들이 생성할 수 있는 vm 총량에 제한을 걸어두었고, 2025년 10월인 현재로선 이를 뚫고 vm을 생성할 방법이 없다.
단, 이는 프리티어 한정이고 유료 계정으로 전환하면 생성이 가능하다. 유료 플랜으로 전환한 뒤 무료 할당량만큼만 사용한다면 과금은 발생하지 않는다. 관련 정보를 찾아보면 많은 실패 사례가 나오지만, 다행히 이미 무료 계정을 발급받아서 사용중이었고, 업그레이드도 별 문제 없이 수행되었다. 단, 이때 지급 방법 검증 차원에서 100달러가 결제되었다가 환불되었다. 하마터면 안될뻔..
k3s 설치
helm 설치
helm 은 k8s 리소스들을 편하게 관리할 수 있도록 해주는 패키지 관리자다. 이를 설치하면 여러 오픈소스들을 활용해 쉽게 k8s 에 어플리케이션을 배포할 수 있다. 설치 역시 간단하다. 공식 홈페이지의 Installing Helm 문서대로 설치하면 된다.
nginx ingress controller 설치
k3s 를 설치하면 기본적으로 Traefik ingress controller 가 설치된다. 기술을 배우는건 재밌는 경험이지만, 지금 나의 목적과는 대치되므로 과감히 삭제하기로 했다. 만약, 삭제하지 않고 nginx ingress controller 를 사용하면 Traefik 이 먼저 트래픽을 가로채어 nginx ingress 설정이 무용지물이 되기도 한다.
OCI(오라클 클라우드)에 K3S 인프라 구축하기
2025/10/12
사이드 프로젝트
Devops
k8s
작성 완료
복제 = 데이터를 여러 위치에 중복 저장해서 안정성 높이는거
샤딩 = 대규모 데이터베이스를 작은 단위(샤드)로 나누어 각각을 별도의 서버에서 다루는 방식
즉, 복제본 세트를 여러 샤드로 나누어 관리하게 된다.
복제본 세트는 하나의 주서버와 여러개의 보조 서버로 이루어짐. 주 서버는 모든 쓰기 작업을 담당, 데이터 변경사항을 oplog 에 저장. 보조 서버는 oplog를 참조해 동일한 작업 수행해 데이터 일관성 유지. 주 서버 장애시 자격을 갖춘 보조 서버가 주서버로 선출되는 과정 시작.
몽고 DB는 분산 시스템의 데이터 일관성 보장을 위해 RAFT 합의 알고리즘 사용. 이 알고리즘에 투표 매커니즘 포함되어있음. 투표는 당므 상황에서 발생
•
복제본 세트의 서버 추가 또는 제거
•
복제본 세트 초기화
•
주 서버와 보조 서버 간 하트비트 지연이 제한을 넘긴 경우(자체 호스팅 = 10초, 몽고 DB 아틀라스 = 5초)
애플리케이션은 자동 장애 조치와 선거 상황에 대응할 수 있도록 설계되어야함.
선거가 완료된 이후에는 일정 시간동안 새로운 선거를 시작할 수 없는 동결 기간 적용 = 연속적인 선거로 시스템이 불안정 상태에 오래 돌입되는 것을 막기 위한 것.
복제본 세트는 새로운 주 서버가 선출되기 전까지 쓰기 작업 불가. 보조 서버에서 읽기가 설정된 경우 읽기는 가능. 일반적으로 주 서버 선출은 평균 12초 이내 소요
복제본 세트에서 주 서버가 모든 작업을 oplog에 기록하고 보조 서버가 이를 비동기적으로 복제해사 각 보조 서버에 사본을 보관해 최신상태를 유지하는거 까지는 알겠어. 복제본 세트의 각 구성 요소가 하트비트를 주고받고, 다른 구성원으로부터 oplog 항목을 가져올 수 있다 → 주 서버가 아닌 다른 구성원으로부터 oplog 를 가져와??
몽고DB 복제 & 샤딩
2025/09/09
키워드 정리중
스팟잇(Spot It!) 사이드 프로젝트 회고

프로젝트 소개
스팟잇(Spot It!)은 팝업 스토어 정보 플랫폼이다. 방문객들은 팝업 정보를 쉽게 확인하고 현장 대기 기능을 활용할 수 있으며, 주최자들은 효과적으로 팝업을 홍보하고 관리할 수 있다.
아직 완성되지 않은 부분이 많지만, 이 글에서는 프로젝트 자체보다는 사이드 프로젝트를 통해 무엇을 배우고자 했고, 실제로 무엇을 얻었는지 공유하려 한다.
사이드 프로젝트를 시작한 이유
1. 빠른 피드백 사이클에 대한 갈증
현직자에게 개발동아리 활동이란
2025/09/02
팀 프로젝트
사이드 프로젝트
작성 완료
감사 로그란?
시스템 상에서 누가, 무엇을, 언제, 어디서, 어떻게 했는지 남긴 기록을 감사 로그라 한다. 쇼핑몰을 운영한다고 생각해보자. 여러명의 쇼핑몰 운영자가 상품을 추가하거나 가격이나 재고 등을 수정할 수 있을 것이다. 이때, 누군가 어떤 상품의 가격을 1원으로 수정했다고 하자. 이건 분명히 쇼핑몰에 엄청난 손해를 가지고 오는 행위다. 그런데, 그걸 어떤 직원이 했는지 알 수 없다면? 정말 난감할 것이다. 또, 쇼핑몰에서 계좌이체, 카드결제, 토스 페이, 카카오 페이, 네이버 페이를 지원한다고 하자. 이런 결제 연동 시스템은 쇼핑몰 입장에선 외부 시스템을 사용하는 것이기 때문에 비용을 내야 한다. 이때, 네이버 페이의 그런데, 실제로는 전체 고객 중 1%만 네이버 페이로 결제하는데 연동 비용이 가장 크다면? 당연히 네이버 페이 연동을 굳이 할 필요가 없을 것이다.
앞서 말한 사례들은 모두 감사 로그를 활용하는 사례들이다. 이런 사례들을 분류하면 크게 4가지 정도로 분류할 수 있다.
•
보안 및 규제 준수: 누가 언제 로그인했는지, 중요한 데이터를 언제 수정했는지 등의 기록을 통해 불법적인 접근이나 비정상적인 활동을 감지하고, GDPR, HIPAA 등 각종 규제 요건을 충족하는 데 필수적입니다. 문제가 발생했을 때 책임 소재를 파악하는 데 결정적인 증거가 됩니다.
•
문제 진단 및 추적: 시스템 오류나 비정상적인 동작이 발생했을 때, 감사 로그를 통해 어떤 순서로 이벤트가 발생했는지를 파악하여 문제의 원인을 신속하게 진단하고 해결할 수 있습니다.
•
운영 모니터링: 시스템의 주요 기능이 어떻게 사용되고 있는지, 특정 기능의 사용 빈도 등을 파적하여 서비스 개선이나 운영 전략 수립에 활용할 수 있습니다.
•
비즈니스 프로세스 검증: 특정 비즈니스 프로세스가 의도한 대로 수행되었는지 확인하고, 누락되거나 잘못된 부분이 없는지 검증하는 데 사용될 수 있습니다.
이렇기 때문에 감사 로그를 남기는 행위는 대단히 중요하다.
감사 로그와 비즈니스 로직
감사 로그는 사실상 시스템의 거의 모든 기능들에 추가적으로 붙어야 한다. 즉, 여러 기능들을 적절한 기준으로 분리하여 코드를 작성하는 일반적인 프로그래밍 방식에서, 각 기능마다 이를 따로 통합해 작성하는 것은 문제가 있다.
횡단 관심사
감사 로그 처럼 시스템 전반에 걸쳐 영향을 주고 사용되는 것을 횡단 관심사를 가진다고 표현한다.
AOP
Java + Spring 진영에서의 감사 로그
감사 로그를 남겨보자.
2025/05/25
키워드 정리중
들어가며
100명 규모의 개발 조직에서 공용 라이브러리를 설계하고 배포한 경험이 있다. 혼자 쓰는 유틸리티 클래스를 만드는 것과, 조직 전체가 쓸 라이브러리를 만드는 것은 완전히 다른 종류의 작업이다.
이 글에서는 구체적인 사내 코드를 공개하지 않고, 대규모 조직에서 공용 라이브러리를 설계할 때 고려했던 원칙들을 정리한다.
원칙 1: 사용하는 쪽 코드가 가장 중요하다
라이브러리 내부 구현이 아무리 우아해도, 사용하는 쪽 코드가 복잡하면 실패한 설계다.
100명이 쓰는 라이브러리에서는, "라이브러리 내부 코드 1줄"을 줄이는 것보다 "사용하는 쪽 코드 1줄"을 줄이는 것이 100배 가치가 있다.
Kotlin 확장 함수의 활용
Kotlin을 쓰는 환경이라면 확장 함수가 강력한 도구다. 기존 클래스의 메서드 체이닝에 자연스럽게 끼어들 수 있기 때문이다.
예를 들어 페이징을 처리한다면, 별도 유틸리티 클래스를 호출하는 것보다 기존 쿼리 빌더에 .paginate(pageable) 형태로 체이닝하는 것이 사용 측에서 훨씬 자연스럽다.
원칙 2: 기본값이 있어야 한다
라이브러리를 도입할 때 설정해야 할 것이 많으면 도입 자체가 꺼려진다. "아무것도 설정하지 않아도 동작하는 기본 구현"을 제공해야 한다.
Spring Boot의 @ConditionalOnMissingBean 패턴이 이에 적합하다. 커스텀 구현체를 등록하지 않으면 기본 구현체가 자동으로 빈에 등록되고, 커스텀이 필요한 팀은 자신의 구현체를 등록하면 기본 구현체가 알아서 비활성화된다.
대규모 조직에서 공용 라이브러리를 설계할 때 생각할 것들
2025/04/01
Kotlin
Spring
아키텍처
키워드 정리중
Exposed란
Jetbrain 에서 만든 코틀린을 위한 ORM 프레임워크다.
공식 깃허브의 소개글이다.
Exposed is a lightweight SQL library on top of a JDBC driver for the Kotlin language. Exposed has two flavors of database access: typesafe SQL wrapping DSL and lightweight Data Access Objects (DAO).
With Exposed, you have two options for database access: wrapping DSL and a lightweight DAO. Our official mascot is the cuttlefish, which is well-known for its outstanding mimicry ability that enables it to blend seamlessly into any environment. Similar to our mascot, Exposed can be used to mimic a variety of database engines, which helps you to build applications without dependencies on any specific database engine and to switch between them with very little or no changes.
왜 JPA 냅두고 Exposed를 쓰나?
JPA는 영속성 컨텍스트와 1차 캐시, 변경 감지 등의 기능을 제공해준다. 이는 분명 편리한 기능이긴 하지만, 반드시 필요한 기능은 아니다. 또한, 이런 기능을 제공하기 위해 JPA와 Hibernate의 구조가 크고 복잡해 이해하기 힘들다.
또한, JPA와 코틀린의 궁합이 썩 좋지 않은 것도 문제다. JPA는 말 그대로 자바를 위한 것이기 때문에, 코틀린 환경에서 이를 사용할 때 문제가 발생하기도 한다. 당장 관련 키워드로 검색해 보면 사례가 많이 나온다. 물론, 대부분의 사례는 이미 명확한 해결법이 존재하기 때문에 문제가 되지 않을 수 있다. 그러나 모든 코드를 코틀린으로 작성한다면, 처음부터 코틀린을 위한 프레임워크를 사용하는 것도 합리적이라 생각한다.
DSL 방식 사용법
Exposed를 사용하는 방식은 공식적으로 DAO 방식과 DSL 방식이 있다. DAO 방식은 Spring Data JPA의 Repository와, DSL 방식은 QueryDSL 과 비슷한 사용 방식을 보여준다. 두 사용법 모두 명시적으로 커넥션을 얻고, 트랜잭션을 시작하는 API를 호출해야한다.
현업의 테이블 구조는 토이프로젝트와는 차원이 다르게 복잡하다. 따라서, 복잡한 쿼리가 필요하고, 이는 DSL 방식을 사용하는 압력으로 작용한다. 그래서, DSL 방식의 사용법을 익혀봤다.
DSL 방식으로 Exposed를 사용하기 위해서 필요한 클래스는 2종류다. 하나는 데이터를 담을 대상인 DTO이고, 다른 하나는 테이블을 표현하는 클래스다. 즉, JPA에서는 @Entitiy 어노테이션을 붙인 클래스가 데이터를 담을 대상이면서 테이블을 표현하는 클래스였지만, Exposed의 DSL 방식에서는 두 역할이 분리되어있다.
Exposed - 코틀린 SQL 프레임워크
2024/12/21
Kotlin
DB
작성 완료
분산 트랜잭션
2PC 패턴
분산 트랜잭션을 관리하는 주체인 코디네이터를 두고, 준비(prepare), 커밋(commit)의 2단계를 거치는 패턴이다.
준비(prepare)
분산 트랜잭션에 참여하는 각 참여자(멤버 트랜잭션)에게 커밋할 준비가 되었는지 확인하는 단계다. 이 시점에 멤버 트랜잭션이 관여하는 행이나 테이블에 락이 걸린다.
각 멤버 트랜잭션은 커밋할 수 없는 상태인 경우 커밋할 수 없다는 응답(abort)을 코디네이터에게 응답하고, 커밋이 가능한 경우 가능하다는 응답(prepared)을 한다.
중요한 점은 멤버 트랜잭션의 커밋 가능 여부를 응답하는 것이지, 이 시점에 커밋이나 롤백이 진행되지 않는다는 것이다.
커밋(commit)
코디네이터가 모든 참여자에게 응답을 받았다면, 그 결과에 따라 커밋이나 롤백을 결정한다. 멤버 트랜잭션 중 하나라도 abort 응답을 했다면 롤백을 진행한다.
각 멤버 트랜잭션이 동시에 커밋이나 롤백이 되는 것이 아니라 시간 차이가 존재하게 된다. 그리고, 각 멤버 트랜잭션은 그 결과가 결정될 때 까지 락을 보유하고 있다.
한번 분산 트랜잭션의 커밋 여부가 결정된다면, 이는 그 어떤 경우에도 번복되지 않는다. 만약, 각 노드가 응답이 없다면 응답 할 때 까지 재요청을 무한히 수행한다.
단점
1.
각 멤버 트랜잭션이 오랫동안 락을 보유한다. ⇒ 지연 시간이 증가할 수 있다.
2.
NoSQL 등은 2PC 패턴을 지원하지 않는다.
분산 트랜잭션 - 2PC 패턴, Saga 패턴
2024/11/18
CS
면접질문
네트워크
작성 완료
면접 진행 과정에서 코틀린에 대해 아는 것이 있냐는 질문을 받았다. 코틀린은 전에 다른 기업 사전과제가 코틀린으로 작성해야 했기 때문에 문법을 살짝 공부한 적 있었다. 그 과정에서 느낀 현대적인 언어인 코틀린이 주는 편안함이 있었다고 말했다. 그런데 그 과정에서 코틀린과 자바를 함께 사용하는 환경에서 롬복을 사용하는데 문제가 있다는 글을 봤다는 이야기를 했다. 그리고 그 이유를 물어보셨다. 모르겠다고 하니 자바 컴파일 과정을 살펴보면 이유를 알 수 있을것이라 하셨다. 그래서 이 글을 쓴다.
자바 컴파일 과정과 롬복
자바 컴파일 과정을 한발 더 깊게 들어가면 다음과 같이 설명할 수 있다.
AST 생성 → 어노테이션 프로세싱 → AST로부터 .class 파일 생성
AST(Abstract Syntax Tree, 추상 구문 트리)
컴파일러는 본격적인 컴파일 과정 전에 소스 코드에 문법적으로, 의미적으로 문제가 없는지 확인해야 한다. 그리고 이를 위해 소스 코드를 분해해 트리 형태로 만든다. 이를 AST(Abstract Syntax Tree, 추상 구문 트리)라고 부른다. 왜 이런 자료구조를 만드는지는 컴파일러를 다루는 전문 서적이나 강의를 찾아보는 것이 좋을 듯 하다.
아무튼 핵심은 코드를 컴파일하는 과정에서 AST를 만들고 이를 활용해 실제 실행 가능한 명령어 형태로 바꾸는 것이다. 따라서, AST를 조작한다면 컴파일 과정에서 소스코드에는 없는 명령어를 추가하도록 유도할 수 있다.
어노테이션 프로세서와 롬복
자바에서 어노테이션을 컴파일 타임에 인식해 새로운 파일을 만들 수 있게 하는 공식 API다. javax.annotation.processing 패키지를 통해 제공되고, Processor 인터페이스를 구현하면 되나AbstractProcessor 추상 클래스를 상속하여 구현하는 것이 권장된다. 이 API를 통해 여러가지를 할 수 있다. Java 소스 코드를 생성하도록 할 수 있고, 필요하다면 다른 형태의 파일이 생성되게 할 수 있다.
어노테이션 프로세서는 기본적으로 존재하는 파일을 덮어쓰는 것을 허용하지 않는다.

그럼에도 불구하고, Lombok은 Java 컴파일러 내부에서 사용하는 API를 사용해 이런 제한을 넘어서 AST를 수정하는 방식으로 동작한다.
코틀린과 자바를 같이 쓸 때 컴파일 과정
코틀린과 자바를 같이 사용하는 환경에선 컴파일 과정이 조금 복잡해진다.
왜 코틀린과 자바를 같이 쓸 때 롬복이 문제가 되나?
2024/11/16
면접질문
Java
Kotlin
CS
작성 완료
얼마전 어떤 기업의 면접에서 이들의 차이를 질문받았다. 제대로 대답하지 못한 것 같아서 다시 정리해보았다.
블로킹과 논블로킹, 동기와 비동기 개념은 공통적으로 한 주체가 다른 주체에게 작업의 실행을 넘긴 상황을 구분하는 개념이다.
블로킹과 논블로킹
블로킹은 다른 주체가 작업을 끝낼 때까지 작업을 넘긴 주체가 다른 작업을 진행할 수 없는 것을 말한다.
반대로 논블로킹은 작업을 넘긴 주체가 다른 작업을 진행할 수 있는 것을 말한다.
즉, 블로킹과 논블로킹은 작업을 넘긴 주체가 넘긴 작업 말고 다른 작업을 계속 할 수 있는지 여부로 구분된다.
블로킹 논블로킹 동기 비동기
2024/11/15
면접질문
CS
작성 완료
성능 테스트
성능이란
도서 실무로 배우는 시스템 성능 최적화에선 성능을 다음과 같이 정의한다.
고객의 특정 업무를 대상으로 운영환경하에서 고객이 수긍할 수 있는 응답시간 내에 처리할 수 있는 거래량
동일한 도서에서 다음과 같은 구절도 나온다.
응답시간은 사용자의 특성과 환경에 따라 요구하는 수준이 다르므로 동일한 응답 시간에 대해 고객마다 만족도는 다르게 나타난다. 이는 모든 시스템과 사용자에게 일률적으로 적용할 수 있는 응답시간의 기준은 없다는 것을 의미한다.
또 다른 도서 전문가가 알려주는 웹 퍼포먼스 튜닝에선 부하 테스트의 계획 단계에서 제시한 개요에는 시나리오가 포함된다. 시나리오의 내용은 다음과 같다.
어떤 부하를 가할지 결정
(어떤 동작을 하는 사용자를 몇 %로 가정하는가)
여러 시나리오를 준비하거나 동시에 병렬로 진행
예 : 로그인 → 달력 표시 → 예약 범위 선택 → 확인 화면 → 예약 실행이라는 동작을 하는 사용자 중 다시 한 번 실행하는 사용자가 5%
위 두 내용을 종합했을 때 서비스 개발자가 테스트해야 할 성능은 서비스 사용자가 서비스를 제대로 사용하기 위해 필요한 응답시간을 만족하면서 처리할 수 있는 거래량이다.
성능의 평가
도서 실무로 배우는 시스템 성능 최적화에선 TPS의 T에 대해 다음과 같이 언급한다.
TPS(Trsansaction Per Second)의 T를 고객의 업무 처리 건수가 되는 것이 고객과의 의사소통을 위해서나 업무 시스템을 평가하는 데 적합하다.
그러나, 시스템을 설계하고 분석하는 엔지니어 입장에서는 서버가 인식하는 트랜잭션 또한 시스템을 이해하고 개선 방향을 수립하는데 중요한 의미를 가진다.
요청 사용자 수가 증가하면 서버가 처리 해야할 요청이 많아지므로 응답시간이 점점 늘어난다. 하지만, 시스템 자원의 여유가 많다면 응답시간의 증가 폭 보다 처리하는 요청 수 증가 폭이 더 커서 TPS가 점점 늘어난다. 그러다가 시스템의 CPU의 약 70%정도를 사용하는 시점에서 시스템의 자원이 부분적으로 부족해 TPS는 일정 수치 내외를 유지한다. 최종적으로 CPU의 약 90%정도를 사용하는 지점부터는 시스템의 자원이 부족해 TPS가 떨어지게 된다.
TPS 증가가 멈추는 지점을 임계점이라 한다. 일반적으로 임계점에서의 동시 요청자 수를 늘리는 것을 목표로 하지만, 서비스의 특성에 따라 TPS가 일정하게 유지되는 구간을 늘리는 것을 목표로 하기도 한다.
성능 테스트
2024/10/06
팀 프로젝트
프로그래밍 일반
운영
작성 완료
무중단 배포 환경에서 신규 버전의 배포
분산된 서버 환경에 새로운 버전이 도입되기 위해선 몇번의 배포가 필요할까?
배포 환경 가정
1.
10대의 WAS 서버가 있다. 한번의 배포란, 특정 빌드 파일을 10대의 서버에 순차적으로 새 버전을 실행시키는 것을 말한다.
2.
데이터베이스는 하나의 Source DB와 하나의 Replication DB로 이중화 되어있다.
3.
데이터베이스의 스키마 변경은 미리 작업을 해두었다. 즉, 데이터베이스는 언제든 구버전의 기능과 신버전의 기능을 위해 준비되어있다.
4.
배포는 각 WAS에 순차적으로 진행되는 Rolling 방식이다.
5.
배포 도중 언제라도 사용자는 서비스를 사용할 수 있어야 한다.
6.
신규 버전은 구버전에서 제공하지 않던 기능을 제공하는 것이 아니라 내부 구현이 변경된 것이라 프론트엔드 레벨의 변경은 없다.
첫번째 생각
두번이면 되지 않을까?
기존 버전에서 생성한 데이터가 데이터베이스에 있을테니, 신규 버전의 쓰기와 읽기 기능, 기존 버전의 읽기 기능이 포함된 중간 버전을 먼저 배포해야 한다. 그리고 모든 서버에 중간 버전이 배포되면 기존 버전의 읽기 기능이 삭제된 신규 버전을 배포하면 된다.
문제점
1.
5번째 서버에 빌드 파일이 배포되는 시점에, 1 ~ 4번째 서버에는 중간 버전이 배포가 되어있다. 따라서, 그 시점에 사용자의 쓰기 요청이 1 ~ 4번째 서버에서 처리된다면 데이터베이스에는 신규 버전의 형태로 데이터가 쓰인다. 그런데, 동일한 사용자의 조회 요청이 6 ~ 10번째 서버에서 처리된다면 이 서버들에는 아직 신규 버전의 읽기가 불가능하므로 적절한 응답을 보내줄 수 없다.
신규 버전을 배포하기 위해 몇번의 배포가 필요할까?
2024/09/20
면접질문
CS
운영
작성 완료
Redis 보다 HTTP 최적화가 먼저다
더 높은 처리량을 보여주기 위해 별도의 덩치가 큰 기술을 도입하는 경우가 있다. 이는 아마도 덩치 큰 기업들에서 이런 기술을 도입해 자신들이 처한 문제를 해결하는 것을 보았기 때문이다. 그 대표적인 것으로 Redis를 뽑았지만 Redis 말고도 뭐 많다. 하지만, 이런 기술들을 도입하기 전에 기초적인 HTTP 레벨에서의 성능 향상을 꾀하지 않는다면 순서가 잘못된 것이다. 그런 의미에서 이번에 HTTP 레벨에서 성능을 향상시키기 위한 기술들이 무엇이 있는지 알아보았다.
HTTP 성능 최적화
HTTP 압축
Accept-Encoding 헤더를 통해 클라이언트가 수용할 수 있는 압축 알고리즘을 나열한다. 그리고 서버에서 이 알고리즘 중 하나를 선택해서 적용하고 Content-Encoding 헤더를 통해 클라이언트에 알려준다.
대표적인 알고리즘으로 gzip 알고리즘이 있다. 물론 이 알고리즘을 직접 구현할 필요는 없고 서버 프로그램(톰캣, nginx 등)에서 지원하며 이를 설정하면 된다.
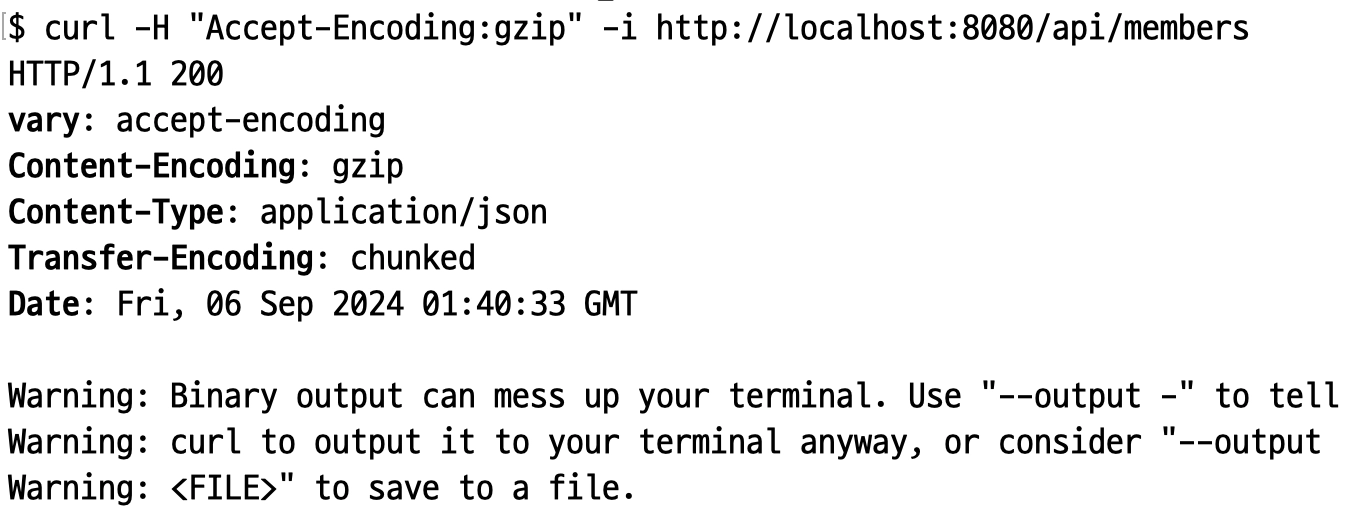
HTTP 압축이 적용된 요청
Vary 헤더
압축과 직접적으로 관련있는 헤더는 아니지만, 압축을 하게 되면 반드시 설정해야 하는 헤더라 설명을 넣어봤다. 이 헤더는 요청의 URL 이나 메서드가 아닌 다른 헤더가 응답에 영향을 주었다면 이를 명시하는 헤더다. 이는 캐시의 키를 생성할 때 사용된다. 즉, 압축을 하므로 이 헤더에 Accept-Encoding 을 값으로 설정해야 한다.


리소스 최적화
HTTP 성능 높이는 방법들
2024/09/06
CS
네트워크
우테코
작성 완료
자바의 Thread
자바에서 스레드 기술은 태초의 Thread 클래스에서 부터 시작했다. 이후 이를 한 층 더 추상화하고, 스레드 풀을 쉽게 만들게 해주는 API가 추가되고, 스레드를 외부에서 종료시킬 수 있는 API가 추가되었다. 그리고 자바 스레드 기술의 최신 버전이 Virtual Thread다. 막 어려운 개념은 아니고, Process 로 동시성을 처리하다가 버거워서 Thread가 등장한 것 처럼, Thread로 동시성을 처리하기 버거워서 Virtual Thread가 등장한 것이다. 성능 향상을 불러오는 근본적인 이유도 같다.
Platform Thread
기존의 자바 Thread 인스턴스다. 이들은 운영체제가 제공하는 스레드를 살짝 감싸서 구현된다. 또한, 생성될 때부터 종료될 때까지 운영체제가 제공하는 스레드에 종속된다. 따라서 Platform Thread개수는 자바가 동작하는 운영체제의 OS Thread 개수에 제한된다.
운영체제는 스레드에 독립적인 스택 메모리 공간을 주고 그 외에도 여러 자원을 할당한다. 따라서, Platform Thread를 사용하는 것은 자바가 동작하는 운영체제의 제한에 크게 영향을 받는다. 대신, CPU 위주의 작업이던, IO 위주의 작업 모두 적절히 수행할 수 있다.
Virtual Thread
가상 스레드 역시 Thread 클래스의 인스턴스다. 다만, Platform Thread와 다르게 운영체제 스레드에 종속되지 않는다. 물론 실행은 운영체제의 스레드 위에서 실행된다.
운영체제 스레드에 종속되지 않기 때문에 Virtual Thread가 blocking I/O 를 사용하면 그 Virtual Thread만 블로킹 될 뿐, 운영체제 스레드는 블로킹 되지 않고 다른 Virtual Thread를 실행한다. 따라서, 컨텍스트 스위칭 비용이 JVM 레벨에서만 발생한다. 이로 인해 더 높은 처리량을 가질 수 있다.
하지만, CPU 연산 위주의 작업을 할때는 Virtual Thread가 적합하지 않다. Virtual Thread는 blocking I/O 상황에서 발생하는 Context Switching 비용을 줄여 높은 처리량을 가지는 것이지, 작업 실행 속도 자체가 빨라지는 것이 아니다.
Virtual Thread의 실행
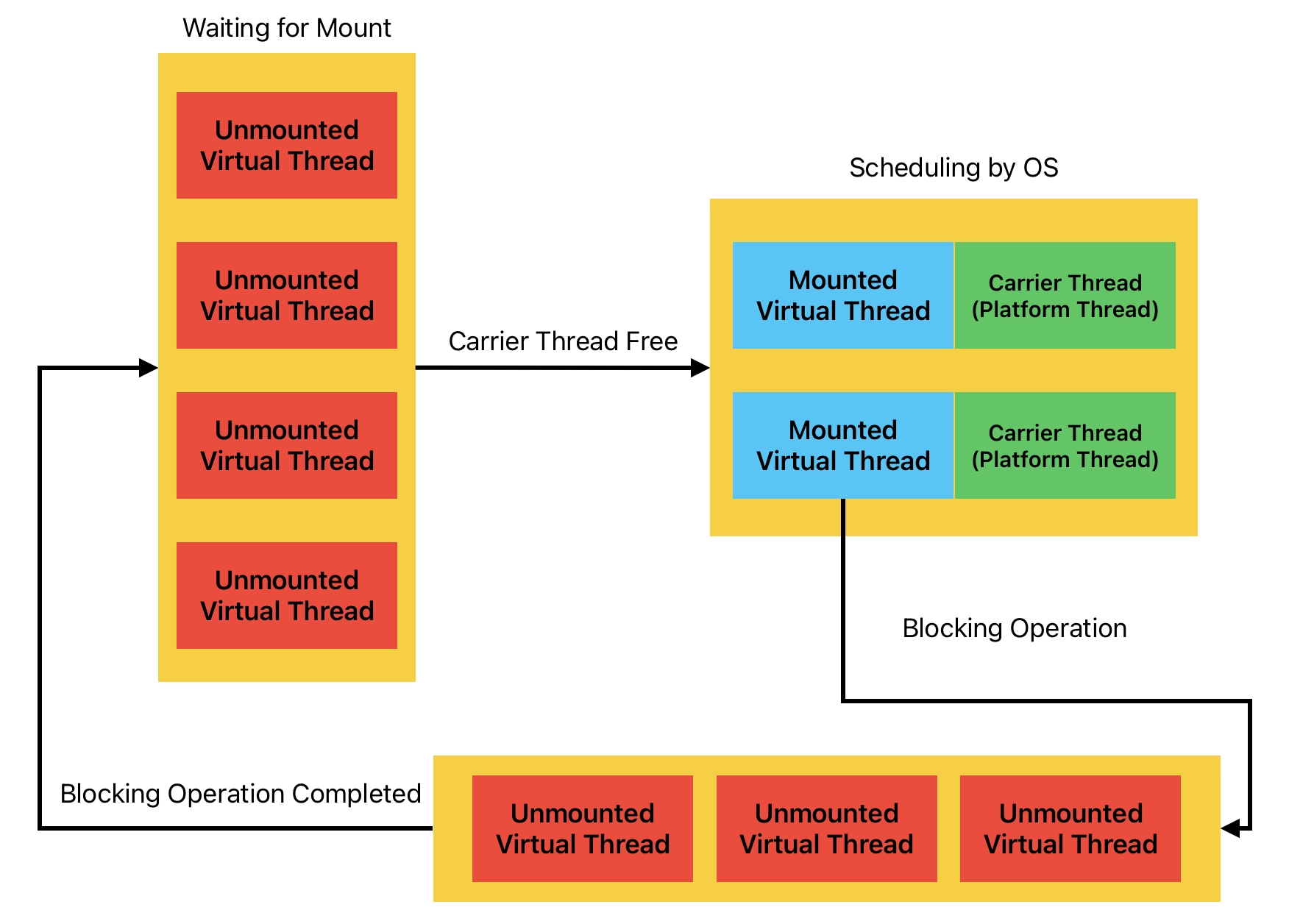
Virtual Thread의 간략한 라이프 사이클
Virtual Thread도 결국 운영체제 위에서 동작하기 때문에 운영체제의 스레드가 Virtual Thread를 실행한다. 따라서 Virtual Thread는 런타임에 동적으로 몇개의 Platform Thread에 매핑되어 작업을 수행한다. 이 mapping 되는 것을 마운트라고 부르고, 마운트된 Platform Thread를 Carrier라고 부른다.
Virtual Thread가 I/O 등 블로킹 작업을 요청하면 마운트가 해제된다. 따라서 Thread 스케줄러가 다른 Virtual Thread 를 마운트 하여 실행할 수 있다. 나중에 Virtual Thread의 블로킹 작업이 완료되면 스케줄러에 제출되고 스케줄러가 이를 마운트한다.
Virtual Thread Pinning
Java Virtual Thread
2024/08/24
Java
CS
면접질문
작성 완료
생각하게 된 계기
우아한테크코스 교육과정에서 “데벨업”이란 이름의 개발자 취준생 커뮤니티 제작 프로젝트를 진행하고 있다. 프로젝트 진행 과정에서 개발 서버와 운영 서버를 분리하게 되었다. 따라서, 두 서버에 다른 이미지로 만들어진 컨테이너가 동작하게 된다. 만약, 이미지 관리를 하나의 레지스트리에서 한다면, 각 서버에서 어떤 이미지를 pull 받아야 하는지 결정하는 과정이 CD 에 추가되어야 한다. 복잡한 작업이 될것이라 예상되어 개발용 레지스트리와 운영용 레지스트리를 분리하는 방법을 찾게 되었다.
상용 서비스 vs 직접 운영
기본적인 레지스트리인 도커 허브에선 무료 플랜에선 프라이빗 레지스트리를 하나만 제공한다. 또 다른 서비스인 깃허브 패키지 역시 무료 플랜에선 용량과 트래픽 제한이 있다. 다른 상용 서비스들도 여럿 있지만, 프라이빗 레지스트리를 위해선 돈을 지불해야 한다. 반면, 직접 운영하는 경우 서버 임대 비용을 제외하면 별도의 비용이 발생하지 않는다. 따라서, 직접 레지스트리를 운영하는 방법에 대해 학습할 가치가 있다고 판단했다.
구축 과정
최종적으로 구현된 자체 레지스트리 웹페이지
위와 같은 레지스트리 웹페이지를 만든 과정을 소개한다.
도커 레지스트리 직접 운영하기
2024/08/18
Docker
보안
운영
작성 완료
Spring Data JPA 쓰니까 쿼리가 이상해졌어!
아니 이걸 왜 다 따로 불러와?
Spring Data JPA 를 이용해 사용자의 예약 목록을 조회하는 페이지에 접근했더니 다음과 같은 쿼리들이 발생했다.(스압 주의)
발생한 SQL
자신의 예약 정보를 조회하기 위해서는 그저 예약, 회원, 예약 시간, 테마 테이블을 모두 join 해서 한번에 쿼리를 작성하면 된다. 비록 쿼리가 복잡해지긴 하겠지만, 저 많은 쿼리를 다 따로 데이터베이스에 전송하면서 생기는 오버헤드보다는 아마 나을 것이다.
fetch type
JPA 에서는 @ManyToOne 과 같이 연관관계를 설정하는 어노테이션에 fetch 옵션을 제공해준다. 이 옵션은 FetchType.LAZY 와 FetchType.EAGER 중 하나로 설정할 수 있다.
LAZY 옵션은 연관 데이터가 실제로 필요한 시점에 조회해와라! 라는 옵션이고, EAGER 옵션은 연관관계를 무조건 조회해와라! 라는 옵션이다. LAZY 옵션은 연관관계의 id 값만 조회해오고, 실제로 연관 데이터가 필요할 때 이 id를 이용해 select 쿼리를 이용해 데이터를 조회한다. 반면, EAGER 옵션은 어차피 모든 연관 데이터를 조회할 것이기 때문에 처음부터 모든 데이터를 조회해온다.
이 옵션은 EntityManager.find 를 호출할 때 적용된다.
Spring Data JPA 너는 참 재밌는 친구구나!
JPA에서는 보다 객체에 가까운 형태의 언어인 JPQL 을 지원한다. JPQL은 연관관계를 이용하여 쿼리를 표현하기 때문에 SQL보다 훨씬 깔끔하고 읽기 좋다. 이를 통해 보다 쉽게 쿼리를 작성하고, JPA 의 구현체가 이 JPQL 을 적절히 번역하여 SQL 로 실행시킨다. JPQL 명령어중 fetch join 이 있는데, 이를 사용하여 쿼리를 작성하면 모든 연관 데이터가 한번에 조회된다.
Query Method
JPQL은 기존의 SQL에 비해 편리하지만 여전히 쿼리를 작성해야 한다. Spring Data JPA에서는 이를 한층 더 편하게 사용할 수 있도록 Query Method 라는 기능을 제공한다. 적절한 규칙을 지켜서 메서드 이름을 정한다면, 그 규칙에 따라 생성된 JPQL이 실행되는 구조다.
@Query
N + 1 문제의 원인과 해결방법
2024/05/27
Java
우테코
JPA
DB
작성 완료
아니 내 코드 다 지우라고?
우테코 레벨 2 3번째 미션을 수행하면서 기존의 JdbcTemplate을 사용한 코드를 Spring Data JPA를 이용하도록 수정하라는 요구사항을 만났다. 그리고 미션을 소개하는 시간에 코치 브라운이 이렇게 말했다.
아쉽지만 기존에 있던 JdbcTemplate 코드는 지우세요!

꼭 그렇게 다 가져가야만 속이 후련하십니까? ㅠㅠㅠㅠ
어떻게 하면 내 코드를 최대한 덜 바꿀까?
레벨 1때도 비슷한 고민을 했다. 그때는 지금의 코드에 어떤 문제가 있었지만, 코드를 최대한 조금 수정하고 문제를 해결하고 싶어했다. 당시에 코치 구구와 이야기 했었는데 구구는 이런식으로 말했다.
지금 엎는게 제일 쉬운 방법이에요.
JdbcTemplate 를 JPA로 손쉽게 갈아껴보자
2024/05/15
우테코
Java
작성 완료
처음 요청을 처리하는 곳은 DispatcherServlet 이다
HTTP 요청을 택배로 비유한다면 DispatcherServlet 는 물류센터에 비유할 수 있다. “(특별한 요청을 위해)보내다”라는 의미의 Dispatch 라는 단어가 붙은 대로 DispatcherServlet은 HTTP 요청을 처리하는 담당 클래스(= 핸들러)에게 HTTP 요청을 보내는 역할을 한다. Spring MVC 는 HttpServlet 을 이용해 클라이언트의 요청을 처리해 응답한다. DispatcherServlet은 Spring이 HttpServlet 을 구현한 구현체다.
DispatcherServlet이 처리해야 하는 작업들
우리가 @Controller 혹은 @RestController 어노테이션을 이용해 만든 컨트롤러에게 HTTP 요청의 처리를 위임해야 한다. 이를 위해선 다음 작업들이 수행되어야 한다.
1.
어떤 컨트롤러 객체를 사용해야 하는지 결정
2.
어떤 메서드를 사용해야 하는지 결정
3.
메서드를 호출하기 위한 매개변수 생성
4.
메서드의 반환값을 HTTP 응답에 적절히 표현
어떤 컨트롤러 객체를 사용해야 하는지 결정 : HandlerMapping
컨트롤러의 인스턴스는 Spring이 시작되면서 복잡한 과정을 통해 생성되어 Spring 컨테이너 내부에서 관리된다.
즉, 컨트롤러 객체는 이미 존재한다.
이 많은 컨트롤러 객체 중 어떤 컨트롤러 객체를 사용해야 하는지 결정하는 것이 HandlerMapping 이다.
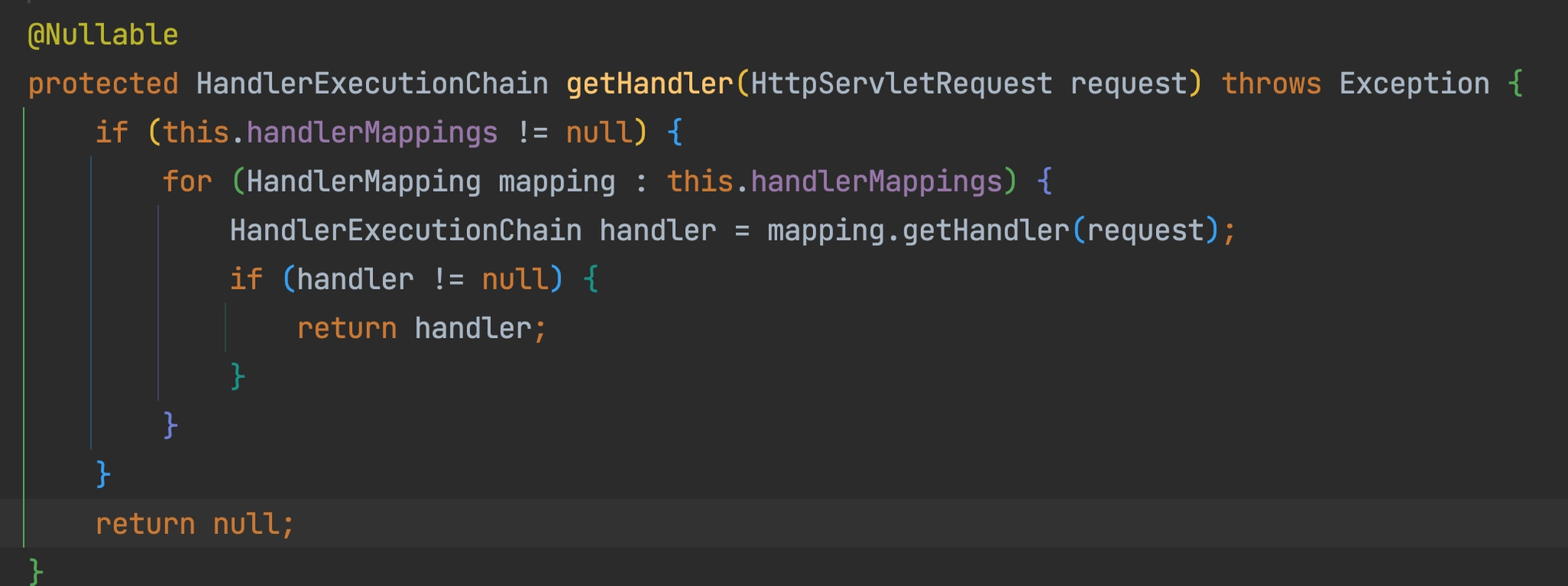
HandlerMapping 은 인터페이스로 Spring과 Spring Boot 내부에 여러 구현체가 있다.
Spring Web MVC 동작 구조 - 대체 내 컨트롤러를 어떻게 실행할까?
2024/05/08
Java
우테코
작성 완료
의존
어떤 요소 A가 동작하기 위해서 다른 요소 B가 필요하다면, A가 B를 의존한다.
Ladder가 동작하기 위해서는 List<Line> 이 필요하다. 즉, Laddder는 List와 Line을 의존한다.
정말 간단하게 자바에서 import 하는 모든 것을 의존한다고 보면 된다. 단, 그게 전부는 아니다.
이하의 글에서 A 를 의존을 하는 쪽, B를 의존 대상 이라 표현한다.
주입
주입의 사전적 의미는 다음과 같다.
어떤 물체 안에 액체나 기체 따위를 집어넣음.
- 네이버 국어사전
어떤 대상의 외부에서, 내부로 무언가를 집어 넣는 것!
의존성 주입
의존을 하는 것이 의존 대상이 되는 것을 직접 만들지 않고, 외부에서 의존 대상을 집어 넣는 것!

조금 더 쉬운 이해를 위해 코드로 살펴 보자
의존성 주입
2024/03/23
우테코
프로그래밍 일반
Java
작성 완료
개요
sealed 키워드에 대해 이해하기 위해서는 자바에서 인터페이스와 추상 클래스, 구체 클래스를 이용한 상속 구조를 이해하고 있어야 한다. 이 포스트는 독자가 이를 이미 이해하고 있다고 가정하고 작성했다.
Java 15에 Preview 로 추가되어 Java 17에 정식 기능으로 포함된 상위 클래스(혹은 인터페이스)에서 자신을 상속(구현)하는 클래스(인터페이스)를 제한하는 기능이다.
도입 배경
인터페이스, 추상 클래스, 구체 클래스를 이용한 견고한 코드
사다리 게임 미션의 요구사항 중 사다리에 대한 제약 조건이 있다.
•
사다리 타기가 정상적으로 동작하려면 라인이 겹치지 않도록 해야 한다.
◦
|-----|-----| 모양과 같이 가로 라인이 겹치는 경우 어느 방향으로 이동할지 결정할 수 없다.
사다리가 랜덤으로 생성되는 것이 타당하지만, 랜덤은 테스트하기 어렵기 때문에 랜덤으로 결정되는 부분을 외부에서 주입할 수 있도록 하는 것이 테스트에 유리하다. 아래는 이를 위한 인터페이스다.
List.of(true) = |-----| , List.of(true,flase,true) = |-----| |-----| 이런 라인과 대응된다.
랜덤으로 Boolean을 집어넣는 구현체를 다음과 같이 작성할 수 있다.
테스트 코드에서는 랜덤이 아니라 지정할 수 있도록 코드를 구현할 것이다. 그런데, 지금 구조에서는 이런 테스트 구현체가 fixInvalidBridges 와 비슷하게 true가 연속해서 나오지 않도록 강제할 수 없다.
sealed , non-sealed
2024/03/16
Java
우테코
작성 완료
아래 글에서 타입, 클래스, 역할, 책임 등의 용어는 객체지향의 사실과 오해 라는 도서를 참고하자.
객체를 어떻게 분류할 수 있을까?
타입(혹은 클래스)가 역할이 동일한 객체를 모은 집합이라면, DTO, VO의 개념은 여러 타입에 부여된 역할이 얼마나 비슷한지에 따른 분류다.
어떤 객체가 DTO 인가? 라는 질문은 그 객체가 속한 타입이 DTO 라는 분류에 속하는가? 라는 질문을 간단히 표현한 것이다.
어떤 역할을 하는 객체가 DTO 일까?
DTO는 데이터 전달 객체다
DTO 는 Data Transfer Object 의 약자다. 직역하면 데이터 전달 객체이다. 즉, 데이터를 전달하는 역할을 가진 객체를 DTO 라고 부른다.
DTO 는 데이터를 전달하는 역할을 가진 객체를 말한다.
데이터를 전달하는 역할을 수행하기만 하면 그것을 DTO라고 부를 수 있다. 즉, 도메인 로직이 구현된 객체를 데이터의 전달에 사용했다면, 그 객체는 DTO라고 할 수 있다.
레이어의 경계를 넘어갈 때 사용하는 것이 DTO다?
누군가는 MVC 패턴, 레이어드 아키텍처 등의 여러 패턴에서 정의한 영역 간의 데이터를 주고 받을 때 사용하는 것이 DTO 라고 말하기도 한다. 이는 DTO의 정의를 편협한 시각에서 내린 것이다.
아키텍처는 나도 만들 수 있다. 따라서 영역이라는 것도 내가 내맘대로 정의할 수 있다.
DTO가 가지면 좋은 특성
하지만, DTO로 분류된 객체가 데이터를 효과적으로 전달하기 위해 가지면 좋은 특징은 분명히 있다.
DTO vs VO
2024/03/08
Java
프로그래밍 일반
작성 완료
Load more
준비 실행 검증 패턴을 사용한 단위 테스트 구성법
3장 : 단위 테스트 구조
단위 테스트
2024/04/02
단위 테스트의 정의
1.
작은 코드 단위를 테스트,
2.
빠르게 수행하고,
3.
격리된 방식으로 처리하는 자동화된 테스트
격리가 무엇인지에 대한 의견 차이가 디트로이트 학파와 런던 학파를 나눈다.
격리에 대한 의견 차이는 테스트 단위에 대한 차이로 이어진다.
런던 학파
테스트 대상 시스템을 협력자에서 격리하는 것 ⇒ 테스트 대상 클래스의 모든 의존성을 테스트 대역(test double)로 대체해야 한다. ⇒ 장점 : 테스트가 실패하면 어디가 고장난건지 확실히 알 수 있다, 객체 그래프(객체 사이의 의존성을 그래프로 그린 것)을 중간에 끊어내고 테스트를 더 간단하게 할 수 있다.
단위 = 단일 클래스
테스트 대역 = 불변 의존성 제외한 모든 의존성
디트로이트 학파
단위 테스트를 격리하는 것 ⇒ 공유 의존성을 데스트 대역으로 대체하는 것
공유 의존성 : 테스트 간에 공유되고 서로의 결과에 영향을 미칠 수 있는 수단을 제공하는 의존성. 정적 가변 필드, 데이터베이스 등이 이에 해당된다.
비공개 의존성 : 공유하지 않는 의존성
프로세스 외부 의존성 : 애플리케이션 실행 프로세스 외부에서 실행되는 의존성. 보통은 공유 의존성이나, 꼭 공유 의존성인 것은 아니다. 예를 들어 데이터베이스는 프로세스 외부 의존성이지만, 테스트마다 컨테이너를 이용해 다른 데이터베이스를 실행시킨다면 공유 의존성은 아니다.
2장 단위 테스트란 무엇인가?
단위 테스트
2024/04/02
그룹화
Collectors.groupigBy
특정 기준에 따라 스트림의 요소를 그룹화 하여 Map으로 만들 수 있다.
만약, 위와 같이 분류된 각각의 리스트에 필터링을 걸고 싶다면, Collectors.filtering()을 사용할 수 있다.
예를 들어 가격이 1000 이상인 것만 남기고 싶다면 다음과 같이 하면 된다.
만약, 위와 같이 분류된 각각의 리스트에 map 을 적용하고 싶다면, Collectors.mapping을 사용할 수 있다.
위와 같이 코드를 작성하면 이름 리스트가 value인 map이 생성된다.
두번째 인자로 또 다른 groupBy를 넣으면, 여러 수준의 그룹화가 가능하다.
분할
Collectors.partitioningBy
6장 : 스트림으로 데이터 수집
IT / 언어
모던 자바 인 액션
정리 완료
2024/02/26
필터링
filter 메서드
Predicate 를 이용해 특정 조건에 맞는 요소만 남기는 필터링이 가능하다.
단, 별도의 연산을 추가하지 않는다면, filter 메서드는 모든 요소에 대해 검사하기 때문에 전체 순회가 발생한다.
distinct 메서드
equals 메서드와 hashCode 메서드로 결정되는 동일한 요소는 하나만 포함하도록 필터링한다.
equals 와 hashCode가 적절하게 정의되어있지 않으면 의도대로 동작하지 않을 수 있기 때문에 주의해야 한다.
스트림 슬라이싱
stream의 일부 영역을 잘라낸 stream을 얻는 메서드 들이다.
takeWhile & dropWhile
Predicate를 이용해 각각 조건에 맞지 않는 요소가 처음 나왔을 때까지 탐색한 요소를 포함하는 stream, 조건에 맞지 않는 요소가 처음 나왔을 때까지 탐색한 요소를 제외한 steream 을 생성한다.
만약, totalMenus가 이미 가격 순으로 오름차순 정렬되었다면 위 코드를 통해 가격이 3000 미만인 메뉴가 선택될 것이다.
5장 : 스트림 활용
IT / 백엔드
IT / 언어
모던 자바 인 액션
정리 완료
2023/09/18 → 2023/09/24
스트림 이란?
자바 8에서 새로 추가된 API 로, 선언형으로 컬렉션을 다룰 수 있게 해주고, 손쉽게 병렬처리를 할 수 있도록 해주는 API이다.
스트림의 우수성
다음 코드는 스트림 없이 작성한 저칼로리의 요리를 반환하는 코드다.
기존의 프로그래밍에 익숙한 사람은 금방 이해할 수 있지만, 임시 변수들도 여럿 사용되었고, 장황한 코드가 많다.
아래는 Stream을 이용한 코드다.
훨씬 알아보기 쉬운 코드가 작성되었다. 심지어 stream() 대신 parallelStream() 을 호출하면 알아서 멀티코어에서 실행된다.
스트림의 정의와 특징
스트림은 ‘데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소’로 정의할 수 있다.
•
연속된 요소 : 컬렉션처럼 스트림은 특정 형식의 요소의 집합에 대한 인터페이스이다. 컬렉션과 다른 점은 요소 저장이나 접근 연산이 아닌, 표현 계산식이 주를 이룬다. 즉, 컬렉션은 데이터 그 자체가 주제이고, 스트림은 계산이 주제이다.
•
소스 : 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 소스로부터 데이터를 소비한다. 데이터 소스의 요소 순서를 유지한다.
•
데이터 처리 연산 : 함수형 프로그래밍에서 일반적으로 제공하는 연산과 데이터베이스와 비슷한 연산을 제공한다. filter, map, reduce, find, sort 등의 연산을 통해 데이터를 조작할 수 있다. 이런 연산들은 순차적으로 혹은 병렬적으로 실행할 수 있다.
4장 : 스트림 소개
IT / 백엔드
IT / 언어
모던 자바 인 액션
정리 완료
2023/09/11 → 2023/09/17
4
람다 표현식
람다 표현식 이란?
익명함수를 단순화 한 것. 람다 표현식을 사용하면 동작 파라미터를 이용하는 코드를 더 쉽고 간결하게 작성할 수 있다.
람다 표현식의 구조
•
매개변수 리스트
•
화살표
•
람다 바디
◦
표현식
◦
여러 행의 문장을 포함하는 블록.
함수형 인터페이스
람다 표현식은 함수형 인터페이스를 표현하는 문맥에서만 사용할 수 있다.
함수형 인터페이스란 추상 메서드를 한개만 가지는 인터페이스이다. 디폴트 메서드나 정적 메서드와는 무관하다.
람다 표현식은 결과적으로 함수형 인터페이스를 구현한 클래스의 인스턴스로서 동작한다.
람다식 활용 : 실행 어라운드 패턴
초기화&준비 코드와 정리&마무리 코드가 실제 작업 코드 앞뒤에 등장하는 형태의 패턴을 실행 어라운드 패턴이라 한다.
3장 : 람다 표현식
IT / 백엔드
IT / 언어
모던 자바 인 액션
정리 완료
2023/09/09
7장부터 11장은 설계 원칙을 다룬다. SOLID 말이다. 이 원칙은 중간 수준의 소프트웨어 구조가 변경에 유연하고, 이해하기 쉽고, 많은 소프트웨어 시스템에 사용할 수 있는 컴포넌트의 기반이 된다. 중간수준이라는 것은 이 원칙을 모듈 수준에서 작업할 때 적용할 수 있다는 뜻이다. 코드 수준보다 조금 상위의 모듈과 컴포넌트 내부에서 사용되는 소프트웨어 구조를 정의하는데 도움을 준다.
SRP 원칙은 모듈이 단 하나의 일만 해야 한다는 의미가 아니다. 이런 원칙은 더 낮은 수준 즉, 코드 수준에서 사용된다.
SRP 원칙
SRP 원칙의 정의
단일 모듈은 변경의 이유가 하나, 오직 하나뿐이어야 한다.
소프트웨어 시스템은 사용자와 이해관계자를 만족시키기 위해 변경된다. 변경의 이유는 곧 시용자와 이해관계자를 가리킨다. 따라서 SRP는 다음과 같이 바꿔 말할 수 있다.
하나의 모듈은 하나의, 오직 하나의 사용자 또는 이해관계자에 대해서만 책임져야 한다.
시스템이 같은 방식으로 변경되기 원하는 사람이 여러명일 수 있기 때문에 이는 집단으로 표현해야 한다. 이를 액터(actor)라고 하자.
하나의 모듈은 하나의, 오직 하나의 액터에 대해서만 책임져야 한다.
모듈은 쉽게 소스파일이라 생각하면 된다. 만일 코드가 소스 파일에 저장되지 않는다면 모듈은 단순히 함수와 데이터 구조로 구성된 응집된 집합이다.
SRP를 위반하는 징후
우발적 중복
Employee 클래스에 calcutePay(), reportHours(), save()메서드가 있다. 이 클래스는 SRP 원칙을 위배한다.
•
calcutePay() : 회계팀에서 기능을 정의 ⇒ CFO에게 보고를 위해 사용
•
reportHours() : 인사팀에서 기능을 정의 ⇒ COO에게 보고를 위해 사용
7장 : SRP, 단일 책임 원칙
IT / 이론
클린아키텍처
2023/06/07
함수형 프로그래밍 개요
함수형 프로그래밍은 사례로 설명하는 것이 가장 좋다.
자바에서 0부터 9까지의 수의 제곱을 출력하려면 이렇게 한다.
함수형 언어인 클로저를 이용하면 이렇게 한다.
•
range 함수는 0 부터 시작해서 끝이 없는 정수 리스트를 반환한다.
•
map 함수는 range 함수가 반환한 리스트를 제곱을 반환하는 익명함수를 이용해 끝이 없는 정수 제곱 리스트를 생성한다.
•
제곱된 리스트는 take 함수로 전달되고, 10 개만 선택되어 println 함수에 전달된다.
눈여겨 봐야 할 것은 자바에서는 i 가 매번 변했지만, 클로저에서는 어떤 순간에도 변수의 값이 변경되지 않았다는 점이다. 즉, 함수형 언어에서 변수는 변경되지 않는다.
불변성과 아키텍처
변하지 않는다면 경합 조건, 교착상태 조건, 동시 업데이트 등이 발생할 수 없다. 당연한 말이지만, 어떤 변수도 갱신되지 않는다면 경합 조건이나 동시 업데이트가 발생할 수 없고, 락이 가변적이지 않으면 교착상태 역시 발생할 수 없다.
다수의 스레드와 프로세스로 인해 발생하는 문제는 가변 변수가 없으면 생기지 않는다.
물론, 현실적으로 가변 변수 없이 시스템을 만드는 것은 불가능하기 때문에 타협해야 한다.
가변 컴포넌트와 불변 컴포넌트의 분리
6장 : 함수형 프로그래밍
IT / 이론
클린아키텍처
정리 완료
2023/05/14
객체지향이 무엇인가?
객체지향을 “데이터와 함수의 조합” 이나 “실제 세계를 모델링 하는 새로운 방법” 으로 설명하는 것은 부족하고 모호한 설명이다.
객체지향을 캡슐화, 상속, 다형성을 통해 설명하는 경우도 있다. 이것이 객체지향의 본질인지 알기 위해선 이것들이 무엇인지를 알아야 한다.
캡슐화
캡슐화는 데이터와 함수를 응집하고, 구분선을 그어 외부에선 내부의 데이터는 은닉되고, 일부 함수들만이 공개되는 것이다.
캡슐화는 객체지향 프로그래밍에 국한된 개념이 아니다. 물론, 객체지향 언어에서 캡슐화를 쉽게 할 수 있는 도구들을 제공해주지만, 동시에 캡슐화를 불안전하게 만든다.
C언어에서도 .h 와 .c 를 분리해서 정보를 감추는 것이 가능하다. 오히려 자바에서의 private, public 을 이용한 캡슐화보다 더 강력하다.
point.h 에 struct 를 선언하고, struct 포인터를 만드는 함수를 선언하고, struct 를 사용하는 함수를 선언한 뒤, point.c 에서 이들을 정의하면, point.h를 include해서 사용하는 main.c 에서는 구조체의 내부에 접근할 수 없다. 심지어, point.c 를 변경하고 싶으면 변경한 뒤 point.c 만 컴파일하면 main.c 은 건들 필요가 없다.
결론
캡슐화는 객체지향의 본질이 아니다.
상속
상속은 결국 변수와 함수를 감싸 하나의 유효범위로 묶어서 재정의하는 것이다.
객체지향 언어는 상속을 편하게 그리고 안전하게 할 수 있도록 해준다. 하지만, 상속이 객체지향 프로그래밍에 국한된 개념은 아니다. C 언어에서도 구조체와 함수 포인터, 형변환을 사용해 상속을 구현 할(흉내 낼) 수 있다. 다만, 이런 방법은 프로그래머가 이를 의도적으로 따라야만 잘 작동한다는 단점이 있다. 객체지향 언어는 상속을 쉽게 할 수 있도록 해준다.
다형성
다형성은 다양한 것으로 하나의 것을 할 수 있는 것이다. STDIN, STDOUT 이 그 예시
5장 : 객체지향 프로그래밍
IT / 이론
클린아키텍처
정리 완료
2023/05/13
데이크스트라의 발견
모든 프로그램은 순차, 분기, 반복으로 표현할 수 있다.
기능적 분해
모듈을 기능적으로 나누는 것을 의미한다.
거대한 문제 기술서를 받아도, 문제를 고수준의 기능들로 분해할 수 있고, 이렇게 분해된 모듈은 제한된 제어구조(순차, 분기, 반복)를 이용해 표현할 수 있다. 이를 토대로 70~80년대에 구조적 분석, 구조적 설계같은 기법이 등장해서 인기를 끌었다.
구조적 프로그래밍은 프로그램을 증명 가능한 세부 기능 집합으로 분해하고, 이를 테스트를 통해 세부 기능들이 거짓(잘못된)임을 증명하려고 시도한다. 테스트를 모두 통과하면 목표에 부합할 만큼 충분히 참이라고 여긴다.
구조적 프로그래밍의 가치
구조적 프로그래밍의 가치는 프로그래밍에서 반증 가능한 단위를 만들어내는 것에 있다.
현대적 언어에서 아무 제약 없는 goto 문장을 지원하지 않는 이유이고, 아키텍처 관점에서 기능적 분해를 최고의 실천법 중 하나로 여기는 이유다.
소프트웨어 아키텍트는 모듈, 컴포넌트, 서비스가 쉽게 반증 가능하도록 만들기 위해 분주히 노력해야 한다.
4장 : 구조적 프로그래밍
IT / 이론
클린아키텍처
정리 완료
2023/05/13
소프트웨어 아키텍처는 코드로부터 시작한다. 코드는 언어와 프로그래밍 패러다임이 발전하면서 변화했다. 따라서, 소프트웨어 아키텍처를 이야기 하기 위해서는 프로그래밍 패러다임을 이야기 해야 한다.
구조적 프로그래밍
구조적 프로그래밍은 무분별한 goto가 해롭다는 사실에서 출발한다. if/then/else do/while/for 등의 구조를 이용해 goto 대체한다.
구조적 프로그래밍은 제어흐름의 직접적인 전환에 대해 규칙을 부과한다.
객체지향 프로그래밍
함수 호출 스택 프레임을 힙 영역으로 옮겨 함수에서 선언된 지역변수를 오래 유지시키는 아이디어에서 등장했다. 이 과정에서, 클래스, 생성자, 인스턴스 변수, 메서드 등의 개념이 생겼다.
객체지향 프로그래밍은 제어흐름의 간접적인 전환에 대해 규칙을 부과한다.
함수형 프로그래밍
수학의 람다 계산법을 프로그래밍에 도입한 것이다. 람다 계산법의 기초가 되는 개념은 기본적으로 심볼의 값이 변경되지 않는다는 불변성이다.
함수형 프로그래밍은 할당문에 대해 규칙을 부과한다.
각 패러다임은 프로그래머로부터 뭔가를 뺏어갔다. 더이상 뺐을게 없기 때문에 새로운 패러다임은 등장하지 않을 것.
패러다임과 아키텍처
객체지향의 다형성을 이용해 아키텍처의 경계를 넘어간다.
함수형 프로그래밍을 통해 데이터의 위치와 접근 방법에 대한 규칙을 부과한다.
3장 : 패러다임 개요
IT / 이론
클린아키텍처
2023/05/11
소프트웨어 시스템은 이해당사자에 행위와 아키텍처 라는 두가지 가치를 제공한다.
개발자는 두가지를 모두 챙겨야 하지만, 현실은 두가지중 덜 중요한 것을 챙기기 위해 중요한 것을 버리는 경우가 많다.
행위
프로그래머는 기능 명세서나 요구사항 문서를 구체화하고, 소프트웨어가 어떤 행위를 하도록 만든다. 소프트웨어가 이를 위반하면 고치는 것이 프로그래머가 해야 할 일이다.
그러나 이런 일이 프로그래머가 해야할 일의 전부가 아니다.
아키텍처
소프트웨어는 soft(부드러운)와 ware(제품)의 합성어다. 즉, 소프트웨어는 ‘부드러움을 지니도록’ 만들어졌다. 부드러움을 지닌다는 것은 변경하기 쉬워야 한다는 말이다.
변경사항 적용의 어려움은 변경의 범위에 비례해야 하고, 변경되는 형태와는 관련이 없어야 한다. 아키텍처는 형태에 독립적이어야한다.
기능과 아키텍처 중 더 중요한 가치
업무 관리자(시스템 사용자)는 당장 원하는 기능이 동작하는 것을 더 중요하게 여길 것이다. 하지만, 개발자는 이 의견에 동조해서는 안된다. 변경이 가능하면 기능이 잘 동작하도록 수정할 수 있기 때문.
아이젠하워 매트릭스
긴급한 문제가 아주 중요한 경우와, 중요한 문제가 아주 긴급한 경우는 거의 없다. 행위는 긴급하지만 매번 높은 중요성을 가지지 않는다. 아키텍처는 중요하지만 즉각적인 긴급성은 가지지 않는다.
우선순위
1.
중요O 긴급O
2.
중요O 긴급X
2장 : 두가지 가치에 대한 이야기
IT / 이론
클린아키텍처
정리 완료
2023/05/10
4
소프트웨어가 동작하도록 하는 것은 쉽다. 소프트웨어를 올바르게 만드는 것은 매우 어렵다.
제대로 만든 시스템 설계와 아키텍처는 아주 적은 인력으로 새로운 기능을 추가하거나 유지보수 할 수 있도록 해준다.
설계와 아키텍처.
설계를 저수준으로, 아키텍처를 세부사항에서 분리된 고수준의 것으로 구분하는 것은 무의미하다. 저수준의 세부사항과 고수준의 구조 모두 소프트웨어 전체 설계의 구성요소이기 때문. 둘은 개별로 존재할 수 있는 것이 아니고, 둘을 구분짓는 경계도 뚜렷하지 않다.
좋은 소프트웨어 설계의 목표
필요한 시스템을 만들고 유지보수하는 데 투입되는 인력을 최소화 하는 데 있다.
설계 품질을 재는 척도는 고객의 요구를 만족시키는데 드는 비용을 재는 척도와 같다. 즉, 기능을 추가할 때 마다 비용이 증가한다면 나쁜 설계다.
코드 정리를 나중으로 미루는 개발자는 결코 코드를 정리하지 않는다. 이것이 반복되고 쌓이면 생산성은 0을 향해 수렴한다.
지저분한 코드는 장기적인 시각에서는 물론 단기적인 시각에서도 항상 깔끔한 코드보다 생산성이 낮아진다.
빨리 가는 유일한 방법은 제대로 가는 것이다.
결론
소프트웨어 아키텍처의 품질을 진지하게 고민하는 것을 하루라도 빨리 하는 것이 좋다.
비용을 최소화하고, 생산성은 최대화 하려면 시스템 아키텍처의 속성을 알아야 한다.
1장 : 설계와 아키텍처란?
IT / 이론
클린아키텍처
정리 완료
2023/04/23
4
