
Redis 보다 HTTP 최적화가 먼저다
더 높은 처리량을 보여주기 위해 별도의 덩치가 큰 기술을 도입하는 경우가 있다. 이는 아마도 덩치 큰 기업들에서 이런 기술을 도입해 자신들이 처한 문제를 해결하는 것을 보았기 때문이다. 그 대표적인 것으로 Redis를 뽑았지만 Redis 말고도 뭐 많다. 하지만, 이런 기술들을 도입하기 전에 기초적인 HTTP 레벨에서의 성능 향상을 꾀하지 않는다면 순서가 잘못된 것이다. 그런 의미에서 이번에 HTTP 레벨에서 성능을 향상시키기 위한 기술들이 무엇이 있는지 알아보았다.
HTTP 성능 최적화
HTTP 압축
Accept-Encoding 헤더를 통해 클라이언트가 수용할 수 있는 압축 알고리즘을 나열한다. 그리고 서버에서 이 알고리즘 중 하나를 선택해서 적용하고 Content-Encoding 헤더를 통해 클라이언트에 알려준다.
대표적인 알고리즘으로 gzip 알고리즘이 있다. 물론 이 알고리즘을 직접 구현할 필요는 없고 서버 프로그램(톰캣, nginx 등)에서 지원하며 이를 설정하면 된다.
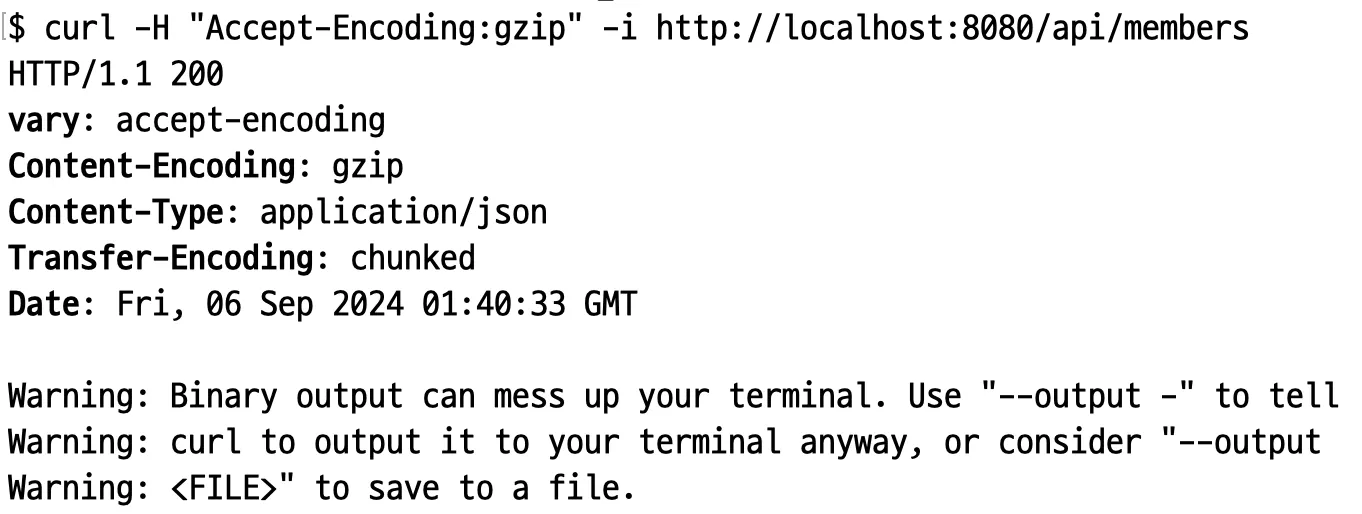
HTTP 압축이 적용된 요청
server:
compression:
enabled: true
YAML
복사
Vary 헤더
압축과 직접적으로 관련있는 헤더는 아니지만, 압축을 하게 되면 반드시 설정해야 하는 헤더라 설명을 넣어봤다. 이 헤더는 요청의 URL 이나 메서드가 아닌 다른 헤더가 응답에 영향을 주었다면 이를 명시하는 헤더다. 이는 캐시의 키를 생성할 때 사용된다. 즉, 압축을 하므로 이 헤더에 Accept-Encoding 을 값으로 설정해야 한다.


리소스 최적화
이미지 압축, JS, CSS minify, 이미지 스프라이트
이미지 압축
이미지 데이터는 이미 전용 알고리즘들(png, jpg 등)이 적용된 상태다. 따라서 앞서 설명한 압축을 적용하면 오히려 압축 오버헤드만 추가되어 성능이 떨어진다.
JS&CSS minify
각종 스크립트 언어는 원칙상으로 없어도 되는 공백이 프로그래머의 편의를 위해 추가되어있다. 또한, 각종 변수명 역시 프로그래머의 편의를 위해 의미를 담아 정한 것이다. 브라우저는 변수명이 a, b 이런식으로 되어있어도 전혀 상관없다. 따라서, JS와 CSS 파일의 공백을 제거하고 변수명을 변경하여 용량을 크게 줄일 수 있다.
모듈 번들러로 유명한 WebPack이 이 기능을 제공한다.
모듈 번들러
JS와 CSS를 처음부터 하나의 파일에 작성할 수 있지만, 개발의 편의성을 생각한다면 여러 파일에 나누어 작성하게 된다. 그러나 이는 몇가지 생각해볼 지점을 만든다.
1.
JavaScript 변수의 스코프
JavaScript 파일을 html 에서 사용하기 위해 이렇게 한다.
<script src="./data.js"></script>
<script src="./index.js"></script>
JavaScript
복사
만약 두 js 파일에 같은 이름의 변수가 있을 경우 동작이 복잡하게 꼬일 수 있다.
2.
여러 번의 통신
위와 같이 여러 js를 따로 지정하면, 당연히 두 스크립트를 받아오기 위한 HTTP 요청을 따로 따로 두번 보내야 한다. 더 많아지면 그만큼 보내야 하므로 성능에 영향을 준다.
이를 막기 위해 여러 JavaScript 파일을 하나의 JavaScript 파일로 만드는 것을 모듈 번들러라고 한다. 이러한 도구로는 Webpack, Rollup, Pacel 등이 있다.
이미지 스프라이트
이미지 스프라이트 예시 - 네이버
이미지 스프라이트는 위 이미지처럼 여러 이미지를 하나의 파일에 합치는 것을 말한다. “이 이미지의 어느 위치에서부터 가로 몇픽셀, 세로 몇픽셀을 보여줘.”라는 의미의 CSS를 작성해 사용한다. 여러 번의 요청을 한번의 요청으로 대체할 수 있으므로 비약적인 성능 향상을 가져온다.
하지만, 이미지가 추가될 경우 다른 모든 이미지의 픽셀 위치가 변경될 수 있어 주의해야 한다. 또한, 이 이미지를 저장하는 웹 서버에 문제가 생길 경우 많은 이미지가 출력되지 않는 사태가 발생하게 된다.
웹 접근성 관점에서도 주의할 점이 있다. 스크린 리더를 사용하는 경우, img 태그를 이용해 표현한 이미지는 스크린 리더가 인식하는 반면, 이미지 스프라이트를 사용한 경우는 인식하지 못한다.
HTTP 캐싱
캐시의 위치

HTTP에서 캐싱 가능한 위치
HTTP에서 가능한 캐싱 위치는 크게 3가지가 있다.
1.
Private Cache : 브라우저에 저장하는 캐시다. 즉, 특정 클라이언트만 사용하는 캐시다.
2.
Shared Cache : 여러 클라이언트가 사용하는 캐시다. Origin 서버와 브라우저 사이에 존재한다.
a.
proxy cache : Origin이 관리하지 않는 캐시다. 낡고 오래된 프록시 같은 경우 최신 스펙의 헤더를 인식하지 못할 수 있지만, HTTPS가 보편화된 지금은 역설적으로 오래된 프록시는 캐싱 자체가 불가능하니 안전하다.
b.
managed cache : Origin이 자신들의 서버의 부하를 분산하고자 의도적으로 관리하는 캐시다. 리버스 프록시, CDN등이 해당된다. 이를 사용하면 의도에 따라 캐싱을 무효화시킬 수 있다. 그야 Origin이 관리하기 때문에 재시작이나 초기화하는 방법으로 캐시를 모두 지워버릴 수 있다.
캐시 동작 과정
캐시를 이용해 응답을 하기 위해선 2가지 조건을 만족해야 한다.
1.
캐시가 존재한다.
2.
캐시가 유효하다.
따라서, 캐시를 관리하는 당사자(브라우저, 프록시 서버, CDN 등)는 이를 확인하는 절차를 거친 뒤 이에 따른 적절한 행위를 수행한다. 캐시가 존재하고 유효한 경우를 Cache Hit, 그렇지 않은 경우를 Cache Miss 라고 부른다.
캐시가 유효한지 판단하는 방식은 여러가지가 있다. 예를 들어, 캐싱을 할 때 부터 캐시의 유효기간을 명시할 수 있다. 다른 방법으로는 각 자원에 고유한 식별자를 부여하고 이것의 일치 여부로 판단할 수 있다.
HTTP 캐시는 클라이언트와 서버가 요청과 응답에 Cache-Control 헤더를 적절히 사용하여 구현된다. 만약, 이런 헤더를 사용하지 않으면 휴시스틱 캐싱이 발생한다. 이는, 캐싱이 어떻게 관리되는지 알 수 없다는 뜻이다. 따라서, 반드시 Cache-Control 헤더를 사용해야 한다.
Cache-Control 헤더에는 정해진 Cache directive를 적을 수 있다. 그리고 이들을 적절히 조합해서 캐싱을 구현할 수 있다.




