

공대생들 사이에서 빛이 되어준 디자이너 바리 님이 만든 이번 서비스 로고 이미지.
오늘 “소규모 학원&과외 선생님을 위한 학생 성적 관리 서비스” Great 의 첫번째 베타 버전이 개발 완료되어 배포되었다. 아직 프로젝트가 완전히 종료된 것은 아니지만 중간정리가 필요할거 같아서, 이렇게 글을 써 본다. 프로젝트를 진행하면서 발생한 여러가지 이슈와 이를 해결하면서 얻은 교훈 등을 정리하고, 끝으로 앞으로 해결해야할 점들을 적어보았다.
이게 왜 됨? 이게 왜 안됨? : 프로젝트는 이슈와 함께
이번 프로젝트에서도, 여러가지 이슈가 있었고 그것들을 해결하면서 여러가지를 배울 수 있었다.
만능 클래스 : 클래스에게 어떤 책임을 부여해야 하는가?
이번 프로젝트의 핵심 도메인에는 “선생님”, “학생”, “시험”, “성적” 이 있다. 따라서, 이들 도메인을 표현하는 클래스들은 여러 기능들에서 등장한다. 그 중 선생님을 표현하는 Teacher 클래스를 예를 들어 살펴보자.
아래는 Teacher 클래스의 코드다.
package com.example.demo.model;
import lombok.Builder;
import lombok.Getter;
@Builder
@Getter
public class Teacher {
private int id;
private Email email;
private Subject subject;
private String nickName;
private Password password;
}
Java
복사
이 클래스는 아래 사진에서 보이는 것 처럼 여러 클래스에서 사용중이다.

Teacher 클래스 사용위치. Teacher의 변경은 잠재적으로 저 모든 클래스들의 변경을 가져올 수 있다.
선생님은 회원가입 시 이메일, 담당 과목, 닉네임, 비밀번호를 입력해야 한다. 이 데이터들은 여러가지 상황에서 사용된다. 이메일과 비밀번호는 로그인을 할 때 사용되고, 담당 과목은 학생을 추가할때 사용된다. 닉네임은 당장은 사용되지 않지만 추후 프로젝트를 확장할때 사용될 예정이다.
그렇다. 이들 정보들은 모두 선생님에 속한 데이터이나, 선생님과 관련된 여러 기능을 수행할 때 항상 필요한 데이터는 아니다. 즉, Teacher 클래스는 회원가입에 사용하기에는 적합하지만, 로그인, 회원정보 수정, 회원정보 조회 등에서 사용하기에는 불필요한 정보들이 포함되기에 적합하지 않다. 따라서 이런 기능들을 구현할때 Teacher 클래스를 사용하는 것은 적합하지 않다.
“적절한 책임” 에 따라 분리되어야 할 클래스라는 뜻이다.
결론적으로 다음 원칙에 따라 클래스들을 분리하였다.

하나의 DTO 는 오직 하나의 API 에서만 사용한다.
또한 패키지 구조를 변경하여, dto 패키지의 하위 패키지로 request, response 패키지를 추가해 각각 클라이언트의 요청 body, 서버의 응답 body 를 표현하는 클래스들을 담도록 하였다.


이 변경을 통해 각 기능들의 상세 스팩 변경이 발생할 시 무엇을 변경해야 하는지 확실하면서도, Side-Effect 를 최소화 할 수 있게 되었다.
인증&인가 : 토큰과 쿠키 그리고 CORS
REST API를 제공하기 때문에 JWT 기반의 AccessToken 과 RefreshToken 2가지 토큰을 이용한 인증방식을 채택했다. 이 인증 방식은 토큰들을 어디에 저장하는지, 토큰에 무었을 저장하는지, 토큰의 유효기간은 어떻게 하는지 등에 따라 많은 차이가 생기게 된다. 이번 프로젝트에선 로그인 시 응답의 body에 AccessToken을, HttpOnly 쿠키에 RefreshToken을 저장하는 방식을 채택하였다. HttpOnly 쿠키는 브라우저를 통해 JavaScript로 접근할 수 없기때문에 리프레쉬 토큰이 탈취될 일이 없으면서도 쿠키는 기본적으로 모든 요청에 자동으로 포함되기에 엑세스 토큰이 만료되어 갱신요청을 보낼때에도 아무 문제가 없기 때문이다. 그렇게 비극은 시작되었다.
@PostMapping("/api/members/login")
public ResponseEntity<ResponseDto<?>> login(@RequestBody LoginDto dto, HttpServletResponse response){
Email email = new Email(dto.getEmail());
Password password = new Password(dto.getPassword());
Tokens tokens= tokenManager.makeTokens(email,password);
String refreshToken = tokens.getRefreshTokenString();
refreshToken = Base64.getEncoder().encodeToString(refreshToken.getBytes());
Cookie cookie = new Cookie("refreshToken",refreshToken);
cookie.setHttpOnly(true);
cookie.setMaxAge(14*24*60*60);
response.addCookie(cookie);
LoginResponseDto responseDto = new LoginResponseDto(tokens.getAccessTokenString());
ResponseDto<LoginResponseDto> result = ResponseDto.<LoginResponseDto>builder()
.response("로그인에 성공하였습니다.")
.data(responseDto)
.code(200)
.build();
return ResponseEntity.ok(result);
}
Java
복사
이렇게 코드로 구현한 다음, PostMan 으로 쿠키가 제대로 전송되는 것까지 확인하고 여러 다른 기능들을 모두 구현하고 개발서버(겸 배포서버.. 분리해야지)에 배포하였지만 프론트엔드 개발자로부터 이런 메시지를 받았다.

토큰 갱신 오류.. 핸들링하지 않은 400?
연락을 받고 로그를 살펴보니, 쿠키가 없어서 400 오류가 난 것이었다. 엥? 분명히 쿠키에 넣었는데? 포스트맨으로 다시 확인해 봐도 여전히 응답에 쿠키가 있었다. 하지만 브라우저에서는 쿠키를 인식하지 못했다. 과거에 다른 프로젝트에서 이런 경험이 있었다. 그때는 CORS 문제였다. 하지만, 이번에는 그때 배운 방법대로 처리해서 CORS 에러는 아니었다.
여러 검색을 통해 다음 사실을 알아냈다.
20년 2월 4일 릴리즈된 구글 크롬(Google Chrome)80버전부터 새로운 쿠키 정책이 적용되어 Cookie의 SameSite 속성의 기본값이 "None"에서 "Lax"로 변경되었습니다.
쿠키에는 서로 다른 도메인간 쿠키 전송과 관련된 설정인 SameSite 속성을 지정할 수 있다. None 으로 설정할 경우 서로 다른 도메인간 쿠키전송이 아무 제약이 없어지는데, 이는 잠재적으로 CSRF 취약점을 발생시킬 수 있기 때문에, 크롬에서 이를 막은 것이다.
현재 전체 시스템 구조를 보면, 백엔드서버는 great.robinjoon.xyz 라는 도메인을 사용하고있고, 프론트엔드의 경우 https://netlify.app/ 을 통해 배포하고 있다. 즉, 두 서버의 도메인이 다르다. 따라서, 백엔드 서버에서 쿠키를 만들어 전달해주어도, SameSite 옵션을 별도로 지정하지 않았기 때문에, SameSite가 Lax로 설정되었고 이로인해 쿠키를 사용하지 않은 것이다.
@PostMapping("/api/members/login")
public ResponseEntity<ResponseDto<?>> login(@RequestBody LoginDto dto, HttpServletResponse response){
Email email = new Email(dto.getEmail());
Password password = new Password(dto.getPassword());
Tokens tokens= tokenManager.makeTokens(email,password);
String refreshToken = tokens.getRefreshTokenString();
refreshToken = Base64.getEncoder().encodeToString(refreshToken.getBytes());
ResponseCookie responseCookie = ResponseCookie.from("refreshToken",refreshToken)
.httpOnly(true).maxAge(14*24*60*60).sameSite("None").secure(true).path("/").build();
response.addHeader("Set-Cookie",responseCookie.toString());
LoginResponseDto responseDto = new LoginResponseDto(tokens.getAccessTokenString());
ResponseDto<LoginResponseDto> result = ResponseDto.<LoginResponseDto>builder()
.response("로그인에 성공하였습니다.")
.data(responseDto)
.code(200)
.build();
return ResponseEntity.ok(result);
}
Java
복사
SameSite 속성을 None 으로 지정하여 이 문제를 해결할 수 있었다.
이 이슈를 해결하면서 여전히 나는 브라우저의 동작에 대해 잘 모르는 것을 깨달았고, SOP = 동일 출처 정책 에 대해 좀 더 학습해야 할 필요성을 느꼈다.
CI & CD : IT 서비스 개발의 MSG, 직접 만들기..?
개발자에겐 CI&CD란 현대인에게 MSG 와도 같다고 생각한다. 조선시대에 자연의 재료로만 음식을 만들던 수라간 상궁에게 미원을 가져다 주는게 CI&CD 없이 개발하던 개발자에게 CI&CD 를 구축하는것과 같다고 할까? 여튼 그래서 CI & CD를 구축하려고 했다.
GitHub Actions 의 장점
1.
사용하는 방법이 매우 쉽다.
깃허브에서 제공하는 것이니 다른 서비스들 처럼 연결을 위한 설정과정이 필요없다. 단지 지정된 경로로 스크립트 파일을 올리기만 하면 동작한다.
2.
설정 스크립트를 오픈소스에서 가져올 수 있다.

마치 우리가 여러 라이프러리를 가져와 쓰는 것처럼 남들이 미리 작성해둔 것들을 가져다 쓸 수 있다. 허들을 낮추는 장점이 될 수 있다.
하지만 얼마 안가 왜 GitHub Actions가 다른 CI&CD 서비스에 비해 인기가 없는지 알게되었다.
GitHub Actions 의 단점
1.
스크립트의 테스트를 위해서는 반드시 커밋을 날려야 한다.
세상의 어떤 언어도 처음부터 완벽하게 오류없이 할 수는 없을 것이다. 당연히 시행착오가 필요한데, 이게 GitHub Actions의 경우 이 설정 파일을 수정하면 반드시 깃허브에 그 변경을 푸쉬해야만 한다. 깃허브에서 이를 인식하고 바뀐 설정을 적용하려면 당연한 것이다. 그런데, 여러번의 시행착오를 겪다보면 커밋 기록이 아주 더러워지는 것은 금방이다. 개발과 직접 관련되지 않은 커밋이 잔뜩 쌓이는 것은 결코 좋은 것이 아니다.
2.
깃허브에 올릴 수 없는 파일들이 있다. 이를 위한 솔루션이 있지만 어딘가 하자가 있다..
깃허브 모든 파일을 올릴수는 없다. DB 연결정보라던지, 각종 암호화 키같은 경우 절대 깃허브에 올려서는 안된다. 하지만, 이 파일들은 당연히 빌드 혹은 테스트과정에서 필요한 파일들이다. 따라서 GitHub Actions 에서 접근할 수 있어야 한다. 이 모순을 GitHub Actions은 secrets 라는 일종의 환경변수 비슷한 것을 제공해 해결한다.
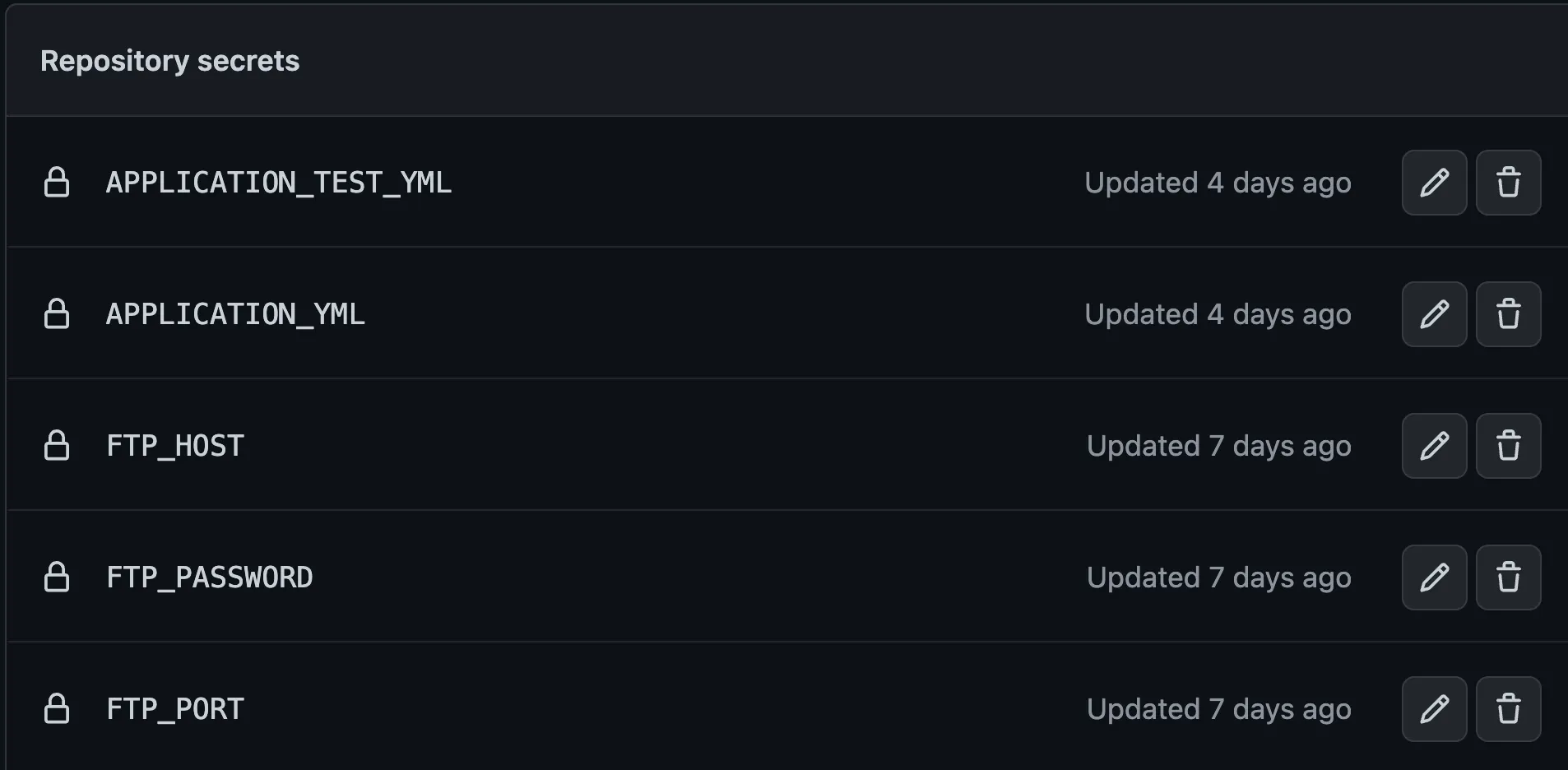
깃허브 레퍼지토리 설정에서 Secrets 를 등록하면 GitHub Actions에서 사용할 수 있는데, 이것을 GitHub Actions 스크립트에서 사용하면

이렇게 마스킹처리 되어 출력로그에 표시된다. 당연히 출력만 그런것이고, 실제로 사용은 된다. 여기까지만 보면 문제가 없어보이지만, Secrets에도 치명적인 단점이 있는데

한번 등록한 Secrets의 삭제나 변경은 가능하지만 정작 조회가 불가능하다.. 즉, 제대로 동작하지 않았을 경우, 현재 어떤 값으로 등록되어있는지 알 방법이 없기 때문에 오류를 수정하기가 매우 어렵게 된다.
이런 단점들을 모두 극복하고 다음과 같은 설정파일을 작성해, ec2 까지 빌드된 파일을 이동시키는 것 까지 성공했다.
# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
# This workflow will build a package using Gradle and then publish it to GitHub packages when a release is created
# For more information see: https://github.com/actions/setup-java/blob/main/docs/advanced-usage.md#Publishing-using-gradle
name: Gradle Package
on:
push:
branches: [ master,develop]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
steps:
- uses: ankane/setup-mariadb@v1
- name: Create DB, DB user, grant permission
run: |
sudo mysql -e "create database if not exists great"
sudo mysql -e "create user 'greatManager'@localhost identified by 'great123!@#'"
sudo mysql -e "grant all privileges on great.* to 'greatManager'@localhost"
- name: read repository
uses: actions/checkout@v3
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
server-id: github # Value of the distributionManagement/repository/id field of the pom.xml
settings-path: ${{ github.workspace }} # location for the settings.xml file
- name: Grant execute permission for gradlew
run: chmod +x gradlew
- name: DB init
run: sudo mysql great < ./src/test/resources/schema.sql
- name: Create application-mailKey.yml
run: |
echo -e "${{ secrets.APPLICATION_YML}}" >> ./src/main/resources/application-mailKey.yml
echo -e "${{ secrets.APPLICATION_TEST_YML}}" >> ./src/test/resources/application-mailKey.yml
- name: Generate Keystore file from Github Secrets
run: |
echo -e "${{ secrets.KEYSTORE}}" > ./key
base64 -d -i ./key >> ./src/main/resources/keystore.p12
- name: Build with Gradle
run: ./gradlew clean build --stacktrace
- name: deploy file
uses: wlixcc/SFTP-Deploy-Action@v1.2.4
with:
username: ${{ secrets.FTP_USERNAME }}
server: ${{ secrets.FTP_HOST }}
port: ${{ secrets.FTP_PORT }}
local_path: './build/libs/*'
remote_path: '/home/j2kb'
sftp_only: true
password: ${{ secrets.FTP_PASSWORD }}
YAML
복사
그런데, 가장 큰 문제가 발생했다.
서버에서 파일을 어떻게 실행하지?
서버에 파일이 업데이트된 것을 감지하면, 현재 실행중인 서버를 종료하고, 업데이트된 파일을 실행시키는 방향으로 동작하게 해야한다. 물론, 도커나 이런 최신 기술들을 이용해, 무중단 배포를 하는 것이 좋겠지만, 우선 급한대로 중단 배포를 하게 구성하기로 했다(도커 공부 해야지..).
중단 배포를 하는 전체적인 로직은 “프로그램이 업데이트 되면, 현재 실행중인 프로그램을 종료하고, 업데이트된 프로그램을 실행한다” 로 정의할 수 있다. 이를 구현하기 위해선 다음 질문을 해결해야 했다.
1.
프로그램이 업데이트 되었는지 어떻게 아는가?
파일의 해쉬값을 이용한다.
2.
현재 실행중인 프로그램의 pid 를 어떻게 알아내는가?
리눅스에 ps -ef 명령어와 grep 명령어를 이용해 현재 실행중인 프로그램의 pid 를 추출할 수 있다.
이제, 방법은 알았으니 구현만 하면 된다. 보통 이런 작업은 쉘스크립트를 작성하고 이를 crontab 과같은 주기적으로 프로그램을 실행시켜주는 것들을 통해 구현하겠지만, 당장 리눅스 명령어들만으로 위의 모든 작업을 할 수 있을거 같지가 않아서, 자바로 프로그램을 작성하기로 했다. 지금 돌이켜 생각해보면, 아주 나쁜 선택이었던 것 같다. 좀 더 생각해보면 리눅스 명령어들만으로 해결이 가능했을텐데..
아래는 그렇게 탄생한 주먹구구식 코드이다. 쪽팔리니까 안봤으면 좋겠다..
그리고 아래는 아는 동생의 반응이다. ㅋㅋㅋ

당신이 무심코 던진 팩트, 맞은 개구리는 죽어요..
이번 경험을 통해 유명한 프로그래밍 격언을 다시 상기할 수 있었다. 바퀴를 다시 발명하지 마라 - Don't reinvent the wheel
앞으로 해야할 것들 : 여전히 남아있는 성장의 가능성
많은 이슈가 있었고, 이를 해결하면서 여러 방면에서 성장했지만, 여전히 남아있는 문제점들이 있다. 이번에는 이 문제점들에 대해 이야기 해보겠다.
만능클래스도 나쁘지만, 융통성 제로 클래스도 나쁘다 : 책임의 적절한 정의
앞의 이슈 설명을 할 때, 만능 클래스를 분리했다는 이야기를 했다. 이 분리를 통해 각 기능들의 상세 스팩 변경이 발생할 시 무엇을 변경해야 하는지 확실하면서도, Side-Effect 를 최소화 할 수 있게 되었다. 하지만 동시에 클래스들의 개수가 아주 방대하게 증가했다. 또한, 각 DTO 들 사이에 중복이 존재한다.
아래 클래스들을 보자. 각각 시험 등록시 사용되는 DTO, 시험 수정시 사용되는 DTO 다.
@Getter
public class AddExamDto {
private String name;
private LocalDate examDate;
private int[] gradeCut;
private String subject;
private int schoolYear;
public String getGradeCut(){
StringBuilder stringBuilder = new StringBuilder();
for (int a : gradeCut) {
stringBuilder.append(a).append(',');
}
stringBuilder.deleteCharAt(stringBuilder.lastIndexOf(","));
return stringBuilder.toString();
}
}
@Getter
public class UpdateExamDto {
private int examId;
private String name;
private LocalDate examDate;
private int[] gradeCut;
private String subject;
public String getGradeCut(){
StringBuilder stringBuilder = new StringBuilder();
for (int a : gradeCut) {
stringBuilder.append(a).append(',');
}
stringBuilder.deleteCharAt(stringBuilder.lastIndexOf(","));
return stringBuilder.toString();
}
}
Java
복사
두 클래스의 차이점은 UpdateExamDto 에 private int examId; 이 필드 하나가 더 있다는 점이다. 그 외에는 이 두 클래스는 완전히 동일하다. 게다가, 이 두 클래스가 다루는 도메인 역시 “시험” 으로 같다. 따라서 이 두 클래스들을 공통 부모 클래스로 묶고 상속한다던지 하는 방식으로 사용한다면 중복을 줄일 수 있을 것이다. 물론, 두 클래스들은 서로를 대체할 수 있는 클래스가 아니니, 같은 부모 클래스를 가지게 하는것이 옳은지는 좀 더 따져봐야 할 수도 있다. 하지만 확실한 건 이 두 클래스는 거의 모든게 중복되었고, 이는 제거 대상이라는 것이다.
이런 관계에 있는 DTO 들이 여럿 있다. 각각의 경우마다 무엇이 더 좋은 선택일지 꼼꼼히 따져봐야 할 것이다.
Controller들의 경우 DTO들과는 또 다르게 문제가 있다.
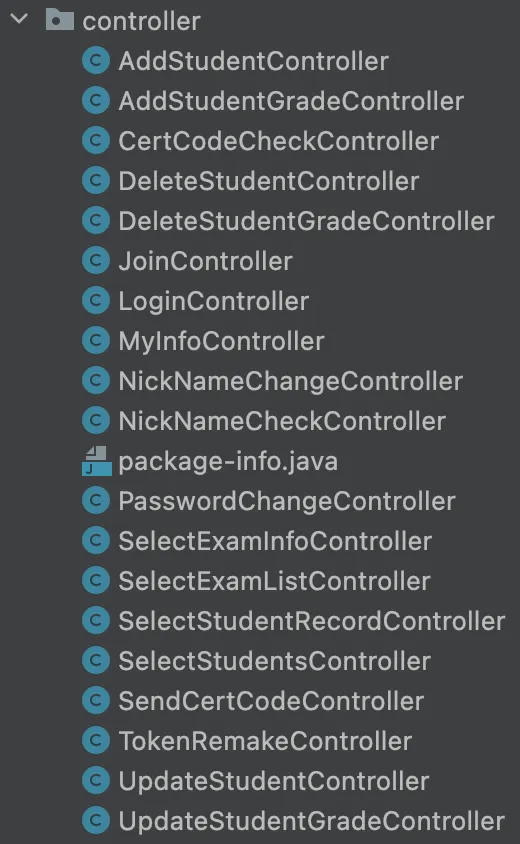
방대한 양의 컨트롤러들. 뭔가 이상하다.
컨트롤러 들도 역시 1 컨트롤러 1 API 원칙으로 구성했다. 물론 “각 기능들의 상세 스팩 변경이 발생할 시 무엇을 변경해야 하는지 확실하면서도, Side-Effect 를 최소화 할 수 있게 되었다.” 는 장점은 여기도 가지고있다. 하지만 Spring Web MVC 에선 기본적으로 각 API 들은 한개의 메서드에서 구현된다. 즉, 애초에 이들은 분명히 서로 구분되어있어 하나의 변경이 다른 API 구현에 영향을 주지 않는다(Servicesk, Repository 단의 변경은 당연히 영향을 줄 수 있지만, Controller 단의 변경에 한정하면). 즉, 굳이 클래스단위로 이렇게까지 분리할 필요가 없다.
이전에 읽은 ⌜객체지향의 사실과 오해 : 역할 책임 협력 관점에서 본 객체지향⌟ 에서는 적절한 책임에 따라 객체에 역할을 부여해야 한다고 이야기 했다. 책임을 너무 많이 지게 해서도 안되지만, 책임을 너무 잘게 쪼개는 것도 지양해야 한다. 추후에 이 컨트롤러들을 핵심 도메인인 “선생님”, “학생”, “시험”, “성적” 단위로 묶는 것이 베스트일것 같다.
우리 DB가 많이 아파요 : 데이터베이스 정규화
바로 이전에 이야기한 주제에서 살펴본 AddExamDto 를 다시 살펴보자.
@Getter
public class AddExamDto {
private String name;
private LocalDate examDate;
private int[] gradeCut;
private String subject;
private int schoolYear;
public String getGradeCut(){
StringBuilder stringBuilder = new StringBuilder();
for (int a : gradeCut) {
stringBuilder.append(a).append(',');
}
stringBuilder.deleteCharAt(stringBuilder.lastIndexOf(","));
return stringBuilder.toString();
}
}
Java
복사
직접 구현한 getGradeCut(); 메서드를 보면, int 배열인 등급컷 정보를 “,” 를 구분자로 하는 하나의 문자열로 만들어 반환하는 것을 볼 수 있다. 이상하다. 이럴거면 애초에 등급컷을 문자열로 전송하게 하는것이 맞을 것이다. 아니 그걸 떠나서, 애초에 왜 등급컷을 문자열로 변경해야 하는가? 그 이유는 우리 DB 가 많이 아프기 때문이다. 아래는 시험 정보를 저장하는 Exam 테이블의 스키마 이다.
CREATE TABLE `exam` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`examDate` date NOT NULL,
`gradeCut` varchar(120) NOT NULL DEFAULT '',
`subject` varchar(45) NOT NULL DEFAULT '',
`schoolYear` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `subject` (`subject`),
CONSTRAINT `exam_ibfk_1` FOREIGN KEY (`subject`) REFERENCES `detailSubjects` (`detailSubject`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
SQL
복사
엥? 등급컷 정보를 문자열로 저장하고 있다. 여러 기능에서 등급컷은 각각의 숫자 하나하나가 독립적으로 의미를 가지게 된다. 즉, 이들을 하나로 묶어 문자열로 관리할 이유가 하나도 없다는 것이다. 클라이언트 사용자가 등급컷을 입력할 때에도 각 등급컷 마다 구분된 입력창에서 입력을 할게 뻔하고, 등급컷을 활용해 그래프를 그릴 때에도 각각의 등급컷은 구분되어 사용된다. 따라서, 등급컷 정보를 exam 테이블에 문자열로 저장할 것이 아니라, 각종 정규화 방식을 사용해 분리하는 것이 옳다. 이걸 모두가 알았지만, 귀찮아서 안했는데 뼈저리게 후회중이다.
그 외에도 학생정보를 저장하는 student 테이블에도 문제가 있다.
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`teacher` int(11) NOT NULL,
`grade` int(11) NOT NULL,
`subjects` varchar(45) NOT NULL,
`school` varchar(45) NOT NULL,
`year` int(4) NOT NULL,
PRIMARY KEY (`id`),
KEY `FK_2` (`teacher`),
CONSTRAINT `student_ibfk_1` FOREIGN KEY (`teacher`) REFERENCES `teacher` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
SQL
복사
학생이 보는 시험과목을 “,”를 구분자로 한 문자열로 저장하고 있다. 이것 역시 무결성이 깨지기 쉽고, 이렇게 할 이유가 하나도 없다. 테이블을 분리해 정규화 해야 한다.
