
스트림 이란?

자바 8에서 새로 추가된 API 로, 선언형으로 컬렉션을 다룰 수 있게 해주고, 손쉽게 병렬처리를 할 수 있도록 해주는 API이다.
스트림의 우수성
다음 코드는 스트림 없이 작성한 저칼로리의 요리를 반환하는 코드다.
List<Dish> lowCaloricDish = new ArrayList<>();
for(Dish dish: menu){
if(dish.getCalories() < 400){
lowCaloricDish.add(dish);
}
}
Collections.sort(lowCaloricDish, new Comparator<Dish>{
public int compare(Dish dish1, Dish dish2){
return Integer.compare(dish1.getCalories(),dish2.getCalories());
}
});
List<String> lowCaloricDishNames = new ArrayList<>();
for(Dish dish: lowCaloricDish){
lowCaloricDishNames.add(dish.getName));
}
Java
복사
기존의 프로그래밍에 익숙한 사람은 금방 이해할 수 있지만, 임시 변수들도 여럿 사용되었고, 장황한 코드가 많다.
아래는 Stream을 이용한 코드다.
List<String> lowCaloricDishNames =
menu.stream()
.filter(d -> d.getCalories() < 400)
.sorted(Comparator.comparing(Dish::getCalories))
.map(Dish::getName)
.collect(Collectors.toList());
Java
복사
훨씬 알아보기 쉬운 코드가 작성되었다. 심지어 stream() 대신 parallelStream() 을 호출하면 알아서 멀티코어에서 실행된다.
스트림의 정의와 특징
스트림은 ‘데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소’로 정의할 수 있다.
•
연속된 요소 : 컬렉션처럼 스트림은 특정 형식의 요소의 집합에 대한 인터페이스이다. 컬렉션과 다른 점은 요소 저장이나 접근 연산이 아닌, 표현 계산식이 주를 이룬다. 즉, 컬렉션은 데이터 그 자체가 주제이고, 스트림은 계산이 주제이다.
•
소스 : 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 소스로부터 데이터를 소비한다. 데이터 소스의 요소 순서를 유지한다.
•
데이터 처리 연산 : 함수형 프로그래밍에서 일반적으로 제공하는 연산과 데이터베이스와 비슷한 연산을 제공한다. filter, map, reduce, find, sort 등의 연산을 통해 데이터를 조작할 수 있다. 이런 연산들은 순차적으로 혹은 병렬적으로 실행할 수 있다.
스트림은 파이프라이닝과 내부반복 이라는 중요한 특징이 있다.
•
파이프라이닝 : 대부분의 스트림 연산은 이들을 연결해 커다란 파이프라인을 구성할 수 있도록 스트림 자신을 반환한다. 이를 통해 게으른 연산, 쇼트서킷 등의 최적화도 얻을 수 있다.
•
내부반복 : 컬렉션과 달리 스트림은 연산 내부에서 반복을 수행한다.
스트림은 한번만 탐색할 수 있다. 즉, 탐색된 스트림의 요소는 소비된다.
Stream<String> stream = menu.stream()
.filter(d -> d.getCalories() < 400)
.sorted(Comparator.comparing(Dish::getCalories))
.map(Dish::getName);
stream.forEach(System.out::println);
stream.forEach(System.out::println); // 일리갈스테이트 예외 발생
Java
복사
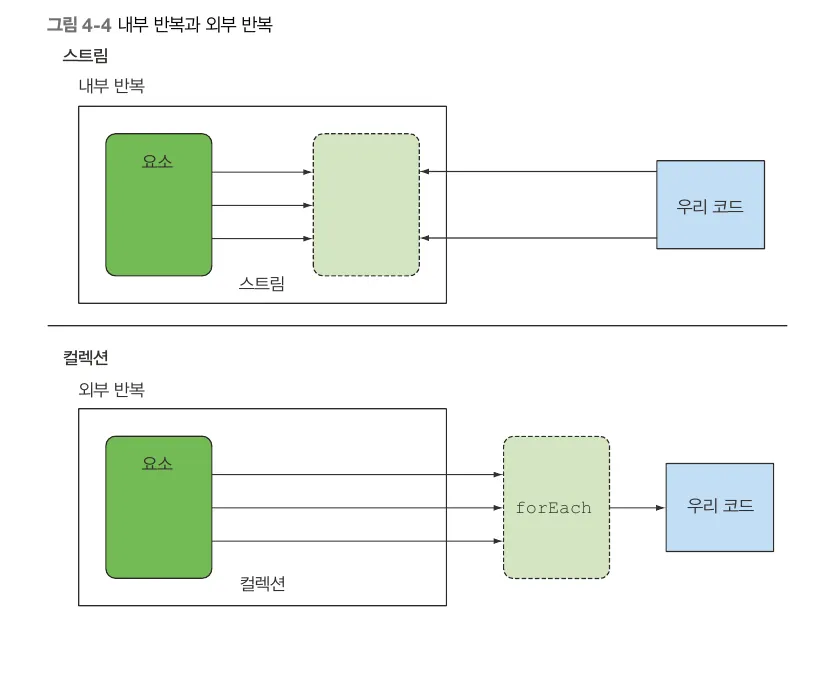
외부 반복과 내부 반복

외부 반복의 비유
외부 반복은 프로그래머가 직접 반복 로직을 작성해야 한다. 핵심적인 처리가 아닌, 단순히 반복하는 것을 구체적으로 기술해야 하는 것은 귀찮은 일이다.
반면, 내부반복은 반복을 API(여기서는 Stream) 에 맡겨서 알아서 효율적으로 반복 처리를 구현하게 할 수 있다. 이를 통해 병렬 처리 역시 손쉽게 가능하다.
결국, 내부반복과 외부 반복의 차이는 반복을 하는 코드를 캡슐화 하는지 여부다.
스트림 연산
스트림 연산에는 다른 스트림 연산을 연결할 수 있는 중간 연산과 스트림에서 어떤 결과를 추출하는 최종(단말)연산이 있다.
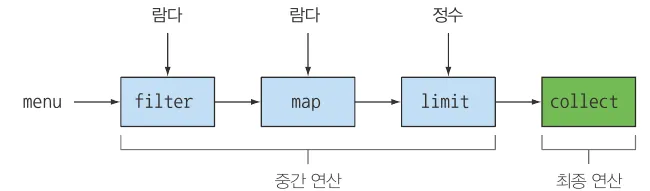
중간 연산은 최종 연산이 호출되기 전에는 아무 연산을 수행하지 않는다. 최종 연산을 호출해야만 중간 연산들을 한번에 연산한다. 이를 게으른 연산 이라 한다. 이런 특성 덕분에 쇼트서킷과 루프 퓨전이라는 몇가지 최적화 효과를 얻을 수 있다.
프로젝트에 적용해보기
이번장에서 맡보기로 나온 스트림 API를 종설 코드에 적용해보았다.
private Map<String,Object> updateProfile(final Map<String,Object> before, final Item item, PersonalizeEvent.RecommendType recommendType){
Set<Map<String,String>> tmp = new HashSet<>((List<Map<String,String>>)before.getOrDefault("recent_items",new ArrayList<>()));
Set<ItemData> recentItems = tmp.stream()
.map(map -> new ItemData(map.get("item_name"), LocalDateTime.parse(map.get("access_time").replace(" ","T"))))
.collect(Collectors.toSet());
ItemData newData = new ItemData(item.getName(), LocalDateTime.now());
recentItems.remove(newData);
recentItems.add(newData);
recentItems = recentItems.stream()
.sorted(Comparator.comparing(ItemData::getAccessTime).reversed())
.limit(5)
.collect(Collectors.toSet());
// 이하 생략
}
Java
복사
List 를 Set 으로 바꾸고, Map<String,String> 을 ItemData 라는 자체 제작한 클래스의 객체로 변환하고, 정렬하는 등의 코드다. Stream 없이 했다면 아주 힘들었을 것 같다.
