



개발공부, 프로젝트한거 정리하는 블로그
전체
Java/Spring
CS
프로젝트
Table
Search
계기
우테코하면서 진행한 프로젝트인 데벨업 프로젝트는 원래 서비스 종료 예정이었으나, 서비스 유지를 원하는 팀원이 있어서 목숨만 부지하고 있었다.
이에 인증서 갱신 등의 작업을 주기적으로 해야 하는데, docker 기반의 인프라로 이를 자동화 하는 것은 상당히 귀찮은 일이다. 마침 회사 업무에서 k8s 를 활용하면서 이런 인증서 발급이나 네트워크 설정들을 k8s 환경에서 구축하는 것이 훨씬 쉽다는걸 깨달았고, 이를 적용해보면 신경쓰지 않아도 될 것 같아 길고 긴 추석 연휴에 이 작업을 수행하게 되었다.
설치 과정
arm VM 생성
오라클 클라우드에서는 익히 알려진대로 arm 기반의 vm 을 4코어 CPU, 24 GB 메모리를 평생 무료로 제공해준다. 하지만, 이런 vm 을 프리 티어 계정에서 생성하는 것은 불가능에 가깝다. 정확히 공지된 바는 없지만, 오라클이 프리티어 사용자들이 생성할 수 있는 vm 총량에 제한을 걸어두었고, 2025년 10월인 현재로선 이를 뚫고 vm을 생성할 방법이 없다.
단, 이는 프리티어 한정이고 유료 계정으로 전환하면 생성이 가능하다. 유료 플랜으로 전환한 뒤 무료 할당량만큼만 사용한다면 과금은 발생하지 않는다. 관련 정보를 찾아보면 많은 실패 사례가 나오지만, 다행히 이미 무료 계정을 발급받아서 사용중이었고, 업그레이드도 별 문제 없이 수행되었다. 단, 이때 지급 방법 검증 차원에서 100달러가 결제되었다가 환불되었다. 하마터면 안될뻔..
k3s 설치
helm 설치
helm 은 k8s 리소스들을 편하게 관리할 수 있도록 해주는 패키지 관리자다. 이를 설치하면 여러 오픈소스들을 활용해 쉽게 k8s 에 어플리케이션을 배포할 수 있다. 설치 역시 간단하다. 공식 홈페이지의 Installing Helm 문서대로 설치하면 된다.
nginx ingress controller 설치
k3s 를 설치하면 기본적으로 Traefik ingress controller 가 설치된다. 기술을 배우는건 재밌는 경험이지만, 지금 나의 목적과는 대치되므로 과감히 삭제하기로 했다. 만약, 삭제하지 않고 nginx ingress controller 를 사용하면 Traefik 이 먼저 트래픽을 가로채어 nginx ingress 설정이 무용지물이 되기도 한다.
OCI(오라클 클라우드)에 K3S 인프라 구축하기
2025/10/12
사이드 프로젝트
Devops
k8s
작성 완료
복제 = 데이터를 여러 위치에 중복 저장해서 안정성 높이는거
샤딩 = 대규모 데이터베이스를 작은 단위(샤드)로 나누어 각각을 별도의 서버에서 다루는 방식
즉, 복제본 세트를 여러 샤드로 나누어 관리하게 된다.
복제본 세트는 하나의 주서버와 여러개의 보조 서버로 이루어짐. 주 서버는 모든 쓰기 작업을 담당, 데이터 변경사항을 oplog 에 저장. 보조 서버는 oplog를 참조해 동일한 작업 수행해 데이터 일관성 유지. 주 서버 장애시 자격을 갖춘 보조 서버가 주서버로 선출되는 과정 시작.
몽고 DB는 분산 시스템의 데이터 일관성 보장을 위해 RAFT 합의 알고리즘 사용. 이 알고리즘에 투표 매커니즘 포함되어있음. 투표는 당므 상황에서 발생
•
복제본 세트의 서버 추가 또는 제거
•
복제본 세트 초기화
•
주 서버와 보조 서버 간 하트비트 지연이 제한을 넘긴 경우(자체 호스팅 = 10초, 몽고 DB 아틀라스 = 5초)
애플리케이션은 자동 장애 조치와 선거 상황에 대응할 수 있도록 설계되어야함.
선거가 완료된 이후에는 일정 시간동안 새로운 선거를 시작할 수 없는 동결 기간 적용 = 연속적인 선거로 시스템이 불안정 상태에 오래 돌입되는 것을 막기 위한 것.
복제본 세트는 새로운 주 서버가 선출되기 전까지 쓰기 작업 불가. 보조 서버에서 읽기가 설정된 경우 읽기는 가능. 일반적으로 주 서버 선출은 평균 12초 이내 소요
복제본 세트에서 주 서버가 모든 작업을 oplog에 기록하고 보조 서버가 이를 비동기적으로 복제해사 각 보조 서버에 사본을 보관해 최신상태를 유지하는거 까지는 알겠어. 복제본 세트의 각 구성 요소가 하트비트를 주고받고, 다른 구성원으로부터 oplog 항목을 가져올 수 있다 → 주 서버가 아닌 다른 구성원으로부터 oplog 를 가져와??
몽고DB 복제 & 샤딩
2025/09/09
키워드 정리중
Exposed란
공식 깃허브의 소개글이다.
Exposed is a lightweight SQL library on top of a JDBC driver for the Kotlin language. Exposed has two flavors of database access: typesafe SQL wrapping DSL and lightweight Data Access Objects (DAO).
With Exposed, you have two options for database access: wrapping DSL and a lightweight DAO. Our official mascot is the cuttlefish, which is well-known for its outstanding mimicry ability that enables it to blend seamlessly into any environment. Similar to our mascot, Exposed can be used to mimic a variety of database engines, which helps you to build applications without dependencies on any specific database engine and to switch between them with very little or no changes.
왜 JPA 냅두고 Exposed를 쓰나?
JPA는 영속성 컨텍스트와 1차 캐시, 변경 감지 등의 기능을 제공해준다. 이는 분명 편리한 기능이긴 하지만, 반드시 필요한 기능은 아니다. 또한, 이런 기능을 제공하기 위해 JPA와 Hibernate의 구조가 크고 복잡해 이해하기 힘들다.
또한, JPA와 코틀린의 궁합이 썩 좋지 않은 것도 문제다. JPA는 말 그대로 자바를 위한 것이기 때문에, 코틀린 환경에서 이를 사용할 때 문제가 발생하기도 한다. 당장 관련 키워드로 검색해 보면 사례가 많이 나온다. 물론, 대부분의 사례는 이미 명확한 해결법이 존재하기 때문에 문제가 되지 않을 수 있다. 그러나 모든 코드를 코틀린으로 작성한다면, 처음부터 코틀린을 위한 프레임워크를 사용하는 것도 합리적이라 생각한다.
DSL 방식 사용법
Exposed를 사용하는 방식은 공식적으로 DAO 방식과 DSL 방식이 있다. DAO 방식은 Spring Data JPA의 Repository와, DSL 방식은 QueryDSL 과 비슷한 사용 방식을 보여준다. 두 사용법 모두 명시적으로 커넥션을 얻고, 트랜잭션을 시작하는 API를 호출해야한다.
현업의 테이블 구조는 토이프로젝트와는 차원이 다르게 복잡하다. 따라서, 복잡한 쿼리가 필요하고, 이는 DSL 방식을 사용하는 압력으로 작용한다. 그래서, DSL 방식의 사용법을 익혀봤다.
DSL 방식으로 Exposed를 사용하기 위해서 필요한 클래스는 2종류다. 하나는 데이터를 담을 대상인 DTO이고, 다른 하나는 테이블을 표현하는 클래스다. 즉, JPA에서는 @Entitiy 어노테이션을 붙인 클래스가 데이터를 담을 대상이면서 테이블을 표현하는 클래스였지만, Exposed의 DSL 방식에서는 두 역할이 분리되어있다.
Exposed - 코틀린 SQL 프레임워크
2024/12/21
Kotlin
DB
작성 완료

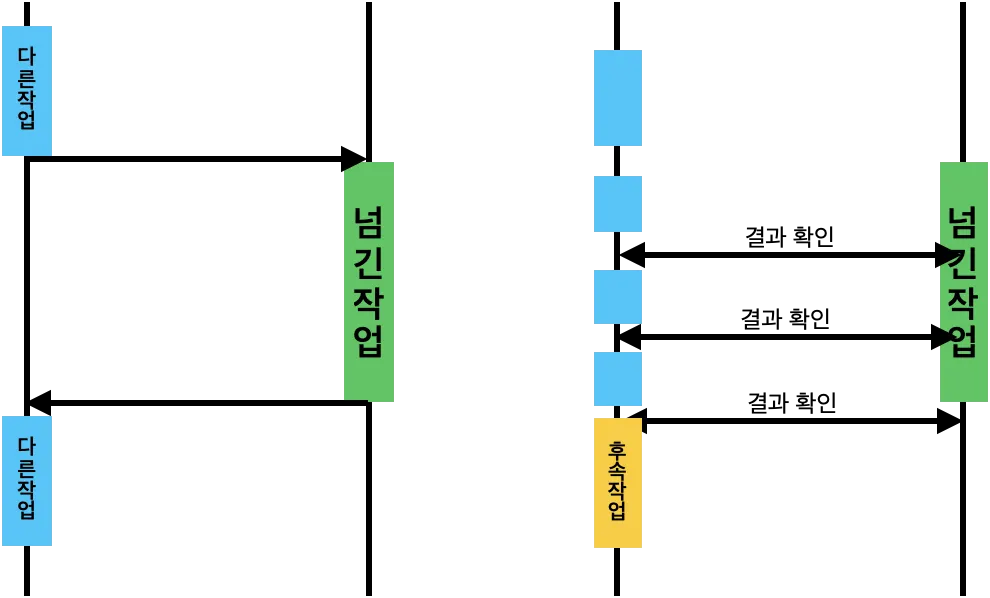
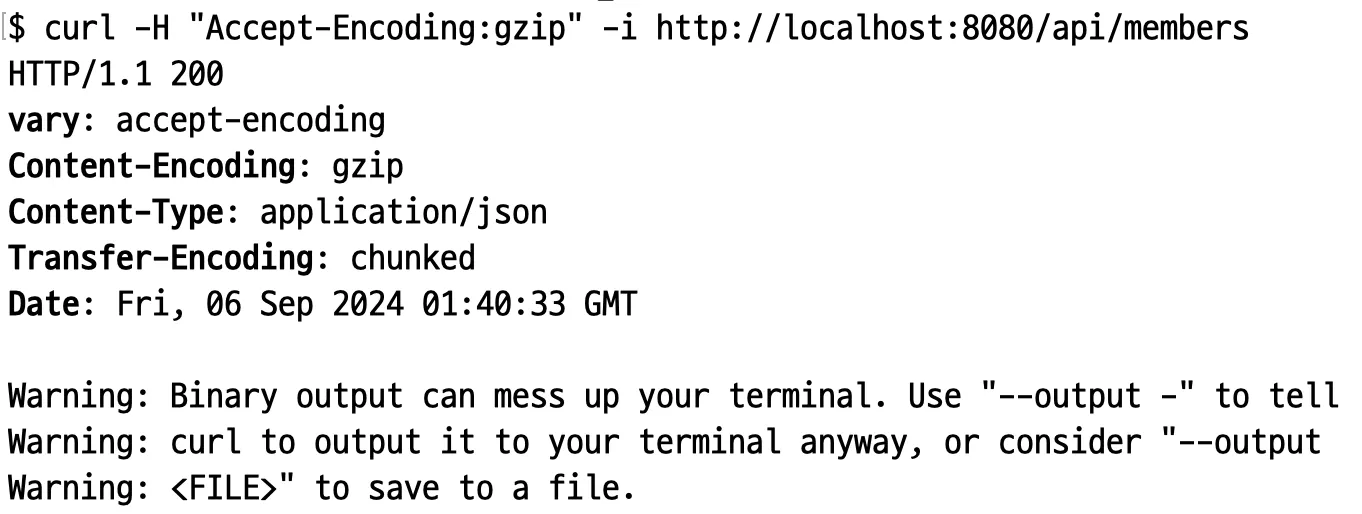


생각하게 된 계기
우아한테크코스 교육과정에서 “데벨업”이란 이름의 개발자 취준생 커뮤니티 제작 프로젝트를 진행하고 있다. 프로젝트 진행 과정에서 개발 서버와 운영 서버를 분리하게 되었다. 따라서, 두 서버에 다른 이미지로 만들어진 컨테이너가 동작하게 된다. 만약, 이미지 관리를 하나의 레지스트리에서 한다면, 각 서버에서 어떤 이미지를 pull 받아야 하는지 결정하는 과정이 CD 에 추가되어야 한다. 복잡한 작업이 될것이라 예상되어 개발용 레지스트리와 운영용 레지스트리를 분리하는 방법을 찾게 되었다.
상용 서비스 vs 직접 운영
기본적인 레지스트리인 도커 허브에선 무료 플랜에선 프라이빗 레지스트리를 하나만 제공한다. 또 다른 서비스인 깃허브 패키지 역시 무료 플랜에선 용량과 트래픽 제한이 있다. 다른 상용 서비스들도 여럿 있지만, 프라이빗 레지스트리를 위해선 돈을 지불해야 한다. 반면, 직접 운영하는 경우 서버 임대 비용을 제외하면 별도의 비용이 발생하지 않는다. 따라서, 직접 레지스트리를 운영하는 방법에 대해 학습할 가치가 있다고 판단했다.
구축 과정
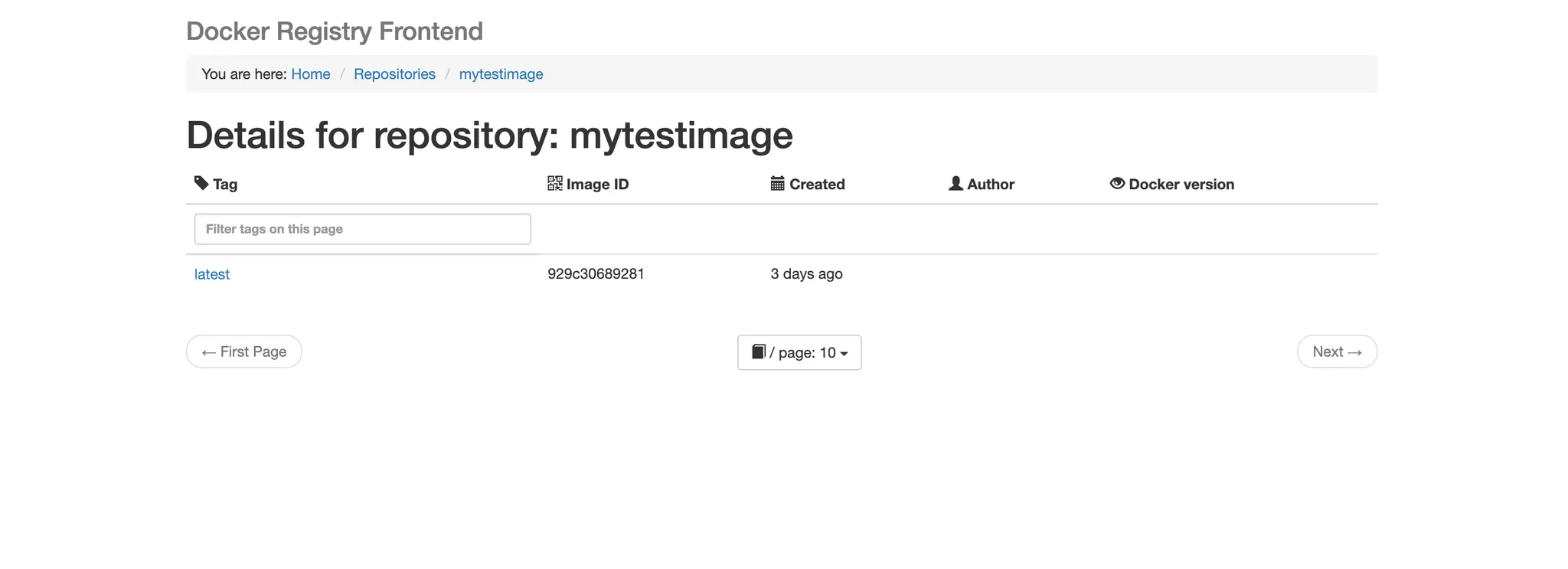
최종적으로 구현된 자체 레지스트리 웹페이지
위와 같은 레지스트리 웹페이지를 만든 과정을 소개한다.
레지스트리 컨테이너 띄우기
compose.yml
레지스트리에 https 적용하기
도커에서 레지스트리가 https 적용이 되어있지 않은 경우 거부하는 것이 기본 설정이다. 예외 설정을 할 수 있지만, 레지스트리를 따로 운영하는 이유가 보안 때문이므로 앞뒤가 맞지 않는다. 따라서 https 를 적용해야 한다고 생각했다.
레지스트리에 https를 적용하는 방법도 있다. 하지만, 추후 웹 UI 도 붙일 것이고 이 곳에도 https 를 적용해야 하는 것이 자명했다. 따라서 https 적용하는 것을 분리하여 nginx를 추가하고 리버스 프록시와 https 를 적용하는 것이 나을 것이라 판단했다. 아래는 이에 따라 변경된 compose.yml 이다.
compose.yml
도커 레지스트리 직접 운영하기
2024/08/18
Docker
보안
운영
작성 완료


의존
어떤 요소 A가 동작하기 위해서 다른 요소 B가 필요하다면, A가 B를 의존한다.
Ladder가 동작하기 위해서는 List<Line> 이 필요하다. 즉, Laddder는 List와 Line을 의존한다.
정말 간단하게 자바에서 import 하는 모든 것을 의존한다고 보면 된다. 단, 그게 전부는 아니다.
이하의 글에서 A 를 의존을 하는 쪽, B를 의존 대상 이라 표현한다.
주입
주입의 사전적 의미는 다음과 같다.
어떤 물체 안에 액체나 기체 따위를 집어넣음.
- 네이버 국어사전
어떤 대상의 외부에서, 내부로 무언가를 집어 넣는 것!
의존성 주입
의존을 하는 것이 의존 대상이 되는 것을 직접 만들지 않고, 외부에서 의존 대상을 집어 넣는 것!

조금 더 쉬운 이해를 위해 코드로 살펴 보자
의존성 주입
2024/03/23
우테코
프로그래밍 일반
Java
작성 완료

Load more
독서록
Search
